Tutorial: Predict hERG Toxicity of Druglike Molecules¶
OpenEye Model Building is a tool to build machine learning models that predict physical property of small molecules.
In this tutorial, we will use the hERG Toxicity floe to predict molecule toxicity as distinct classes of ‘High’ or ‘Low’. The floe predicts the hERG Toxicity of each molecule and explains the prediction based on chemical moeity. It also gives confidence intervals and other insightful information. The floe report provides a summary of the output.
Note: All other pretrained floes to predict molecule properties work the same way.
This tutorial uses the following Floe:
hERG Toxicity Prediction for Small Molecules using ML and Cheminfo Fingerprints
Create a Tutorial Project¶
Note
If you have already created a Tutorial project you can re-use the existing one.
Log into Orion and click the home button at the top of the blue ribbon on the left of the Orion Interface. Then click on the ‘Create New Project’ button and in the pop up window enter Tutorial for the name of the project and click ‘Save’.
Orion home page¶
Floe Input¶
The input dataset contains several OERecord (s). The floe expects an OEMol from each record. These are the molecules for which the model will predict hERG toxicity. Note: uploading .csv, .sdf and other common fileformats to Orion should automatically convert them to datasets. Let this dataset be P_1
Here is a sample record from the dataset:
OERecord (
Molecule(Chem.Mol) : c1ccc(c(c1)NC(=O)N)OC[C@H](CN2CCC3(CC2)Cc4cc(ccc4O3)Cl)O
)
There can be another string field containing hERG Toxicity values (as ‘High’ and ‘Low’) to validate against. The following dataset does not contain said field.
Input Data
Run hERG Toxicity Floe¶
Click on the ‘Floes’ button in the left menu bar
Click on the ‘Floes’ tab
Under the ‘Categories’ tab select ‘OpenEye Model Building’ package
In the search bar enter hERG Toxicity
A list of Floes will now be visible to the right
Launch the floe hERG Toxicity Prediction for Small Molecules using ML and Cheminfo Fingerprints and a Job Form will pop up. Specify the following parameter settings in the Job Form.
For the Input Dataset, choose P_1 from above
All the molecules predicted will be saved to the name in the field Output hERG Toxicity. Change the default name to something recognizable.

That’s it! Things should run, generate an output and a floe report
Analyze OEModel Floe Report¶
Here is a sample image of what the floe report should looks like:
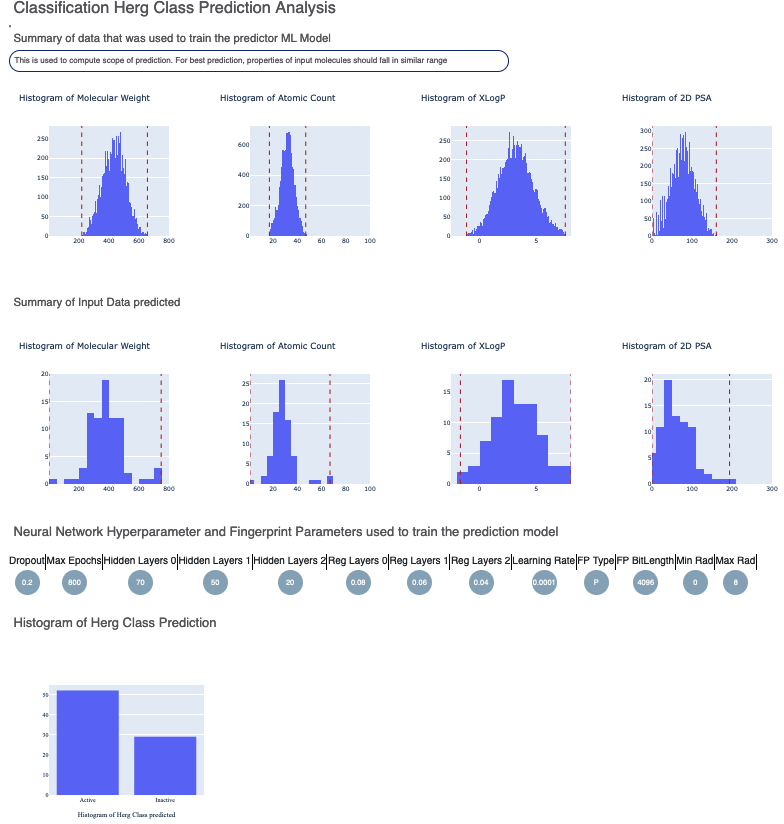
The top part contains the histogram summary of training data versus input. This is followed by the histogram of prediction summary.
Then we have histogram of the output prediction, and the confidence with each prediction. We also have a plot for confidence of prediction versus the actual output. These overall statistics help analyze the input molecules predicted.
Analyze Output¶
Go to the data section of Orion and Activate the data the floe produced. This should have the same name you chose for the Output hERG Toxicity field of your floe. The data can be activated by clicking on the small plus sign in a circle right next to it.
Now going to the analyze page in Orion, you should be able to see the molecules, their predicted pyrrolamide values, and the explanation of the output.
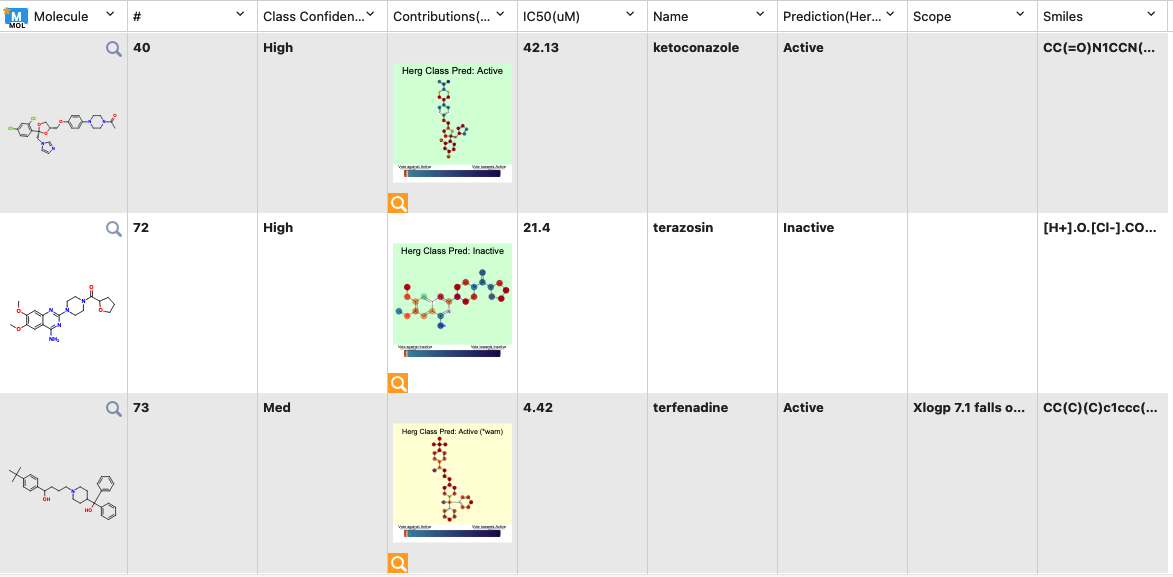
The output columns and their explanations are:
Class Confidence(hERG Toxicity): How confident the Model is with its prediction on High, Med, Low
Contributions(hERG Toxicity): Explanation of prediction based on a local model. If the image has a red/yellow background, it means there is an error or warning issued. Based on the choice of molecule explainer (Atom by default), different parts will be color annotated with red denoting ‘vote against hERG active’ while blue denotes the opposite.
Scope: if there is an error or warning, what caused the issue
Predict(hERG Toxicity): Predicts Toxicity as High or Low. Background color suggests how confident the model is with green (most confidence), yellow(average confidence), and red(less confidence/out of scope)
Note
We assign IDs (#) on each record molecule. This follows a linear ordering over all molecules. So if you activate both the successful and failure predictions, and sort them based on #, the order should be the same as the input.