Computational Resources
In our cookie factory, an important best practice is to minimize the resources spent on performing the tasks needed at the individual assembly lines. In this chapter, we will discuss the best use of cube groups to minimize cost of sending data from one cube to another.
Cube groups allow developers to declare which cubes should run on the same EC2 instance in Orion®. In our metaphor, cube groups represent factory halls housing two or more workstations. Keeping work stations in the same factory hall eliminates the need to prepare and transport the outputs from one station to the next. In a workfloe this translates into lowering serialization and overhead costs. An optimized assembly line might look like this:
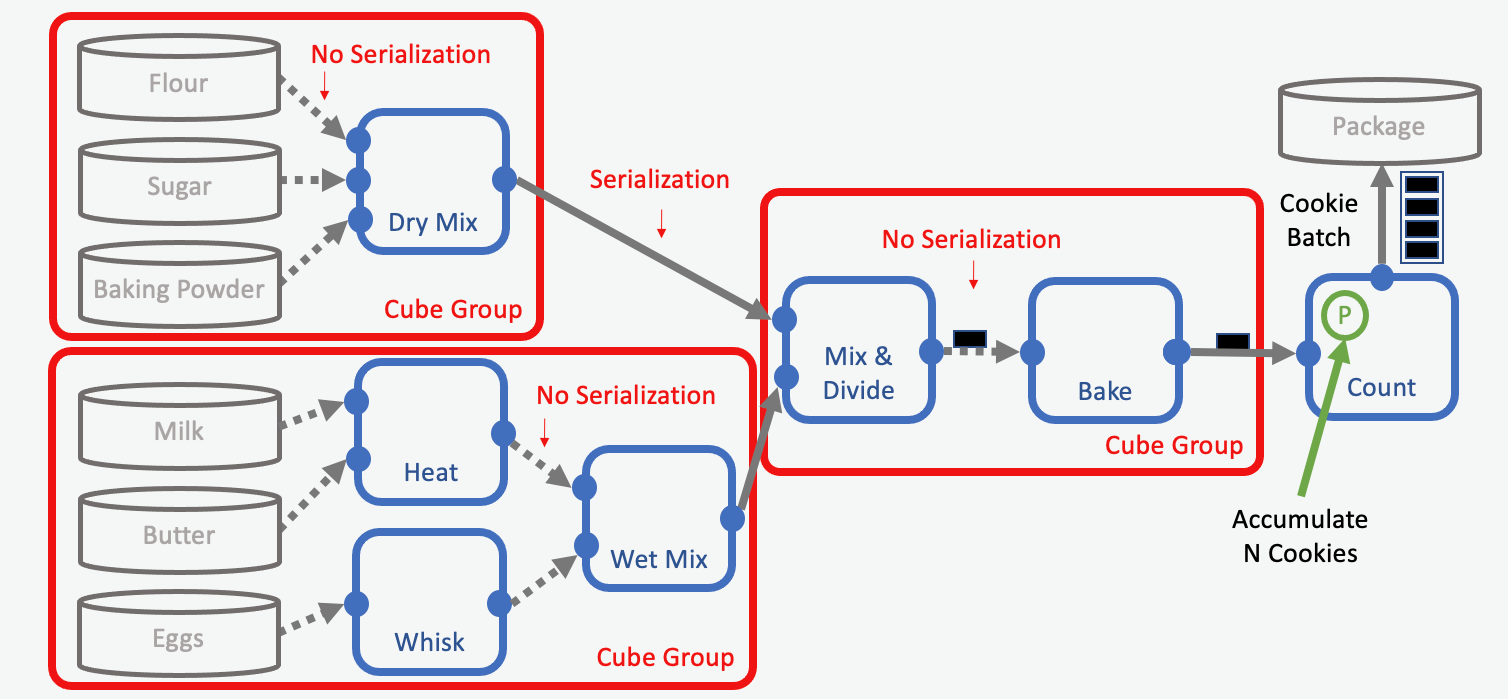
Cube Groups: Putting Multiple Stations in the Same Building
In our optimized example, we group the retrieval of the ingredients (data reading) together with some of the processing steps (mixing). Also, we group the mixing of the dry/wet ingredients with the baking step in a cube group.
Our goal is to spend as little time as possible to transport intermediates between factory buildings (EC2 instances). Any number of cubes can be put into a cube group, as long as they all follow the criteria required to do so. But there are a couple of things to consider:
Individual cubes can have different hardware requirements (CPU, GPU, RAM, disk space, and so forth). The selected EC2 instance needs to serve the sum of requirements for each cube in a group. Thus, developers need to select an EC2 instance with, for example, enough memory for all its grouped cubes. Sometimes only expensive EC2 instances can fulfill such requirements, and in those cases it would be costly to use large cube groups (See “Cube Group Limitations” below for more details).
Individual cubes can have different processing speeds. Grouping slow cubes with cubes with special hardware requirements (for example GPUs) can become costly, because an expensive EC2-instance could be kept busy longer than required. In our cookie making example, it would be wasteful to heat the ovens long before mixing the cookie dough.
Transportation Costs
Having multiple buildings in an assembly line requires the transportation of intermediates from one factory hall to another. This transportation comes with costs that developers should minimize. There are two types of costs: Serialization and overhead.
Serialization
Serialization is the process of converting a complex object to a binary representation that can be sent, byte by byte, over the network. The object is then restored to its original, more complex, structure at the processing end. How the conversion of data is done during serialization is important, and is discussed in detail here.
Overhead
When we think of overhead, we are mainly referring to the cost of sending data over the network. An extreme example of different overhead cost would be sending the link of a collection (low overhead) versus sending all its data (high overhead). It is best practice to send only required data and to remove unnecessary data from the respective cube outputs as early as possible. This topic is discussed in detail here.
Cube Group Limitations
Cube groups represent an effective way to save on transportation costs. However, there are limits to which cubes can be grouped together:
Serial and parallel cubes cannot be grouped together. Serial cubes need to be in “regular” cube groups, while parallel cubes use their own parallel cube groups.
Cubes for closing Shards need to be outside of any cube group. The reason here is the way duplicates and automatic cube restarts work in Orion®.
Cubes with an init port cannot be grouped with the cube that is sending data to the init port. This is because of how the init ports sets the initial “state” of the entire cube group, which cannot include the cube that also sets this state. That is, a cube group acts as a single cube, and cannot initialize itself, but must be initialized by a cube outside the group.
Note
An easy way to detect issues in your cube groups is to use floe lint.
When selecting an EC2 instance type for a compute group, it is important to consider the hardware requirements for the group:
Requirements are universal and shared for the entire cube group.
Requirements could be number of CPUs / GPUs, memory, disk space, et cetera
Make sure that all cubes in a group have the SAME hardware parameters!
Example 1: Cube A and Cube B both need 1 CPU and 16GB of RAM. Since the hardware requirements are similar, we could optimize by putting them in a cube group. However, since both cubes in the cube group runs concurrently, we need to set the hardware requirements for both cubes to 32GB and 2 CPUs. That way the cube group assigns both cubes to an EC2 instance with enough RAM and CPUs for running both cubes simultaneously.
Example 2: Cube A needs 8GB RAM, 124GB Disk space and 1 CPU. Cube B Needs 32GB RAM, 4GB Disk and 1 GPU. In this case, the hardware requirements are very different between the two cubes and it may be better to keep them in separate cube groups. Especially because EC2 instances with GPUs tend to be more expensive than CPU instances. It could be costly to have a GPU assigned to a cube group during the entire runtime of both cubes.