Parallelization
One way to optimize the runtime of a floe is to eliminate potential bottlenecks by speeding up slow tasks using parallel cubes. Parallel cubes can process multiple items (such as Records) simultaneously. In our cookie making factory, multiple ovens can be used for baking cookies at the same time. The challenge is to use parallel cubes correctly and only when needed.
Parallelization is useful when the following criteria are met:
Processing of one item is independent of processing another.
Slow cube(s) would be a bottleneck.
The task scales with the number of inputs.
Each item can be processed in less than 11.5 hours.
No global descriptors/results about the items (average size, et cetera) are being calculated.
No specific pairing of items from different input ports is needed (no bookkeeping required).
No batching of data is performed.
Downstream cubes can easily keep up with output of the parallel cube (no stalling).
Parallel Cubes: Processing multiple records simultaneously
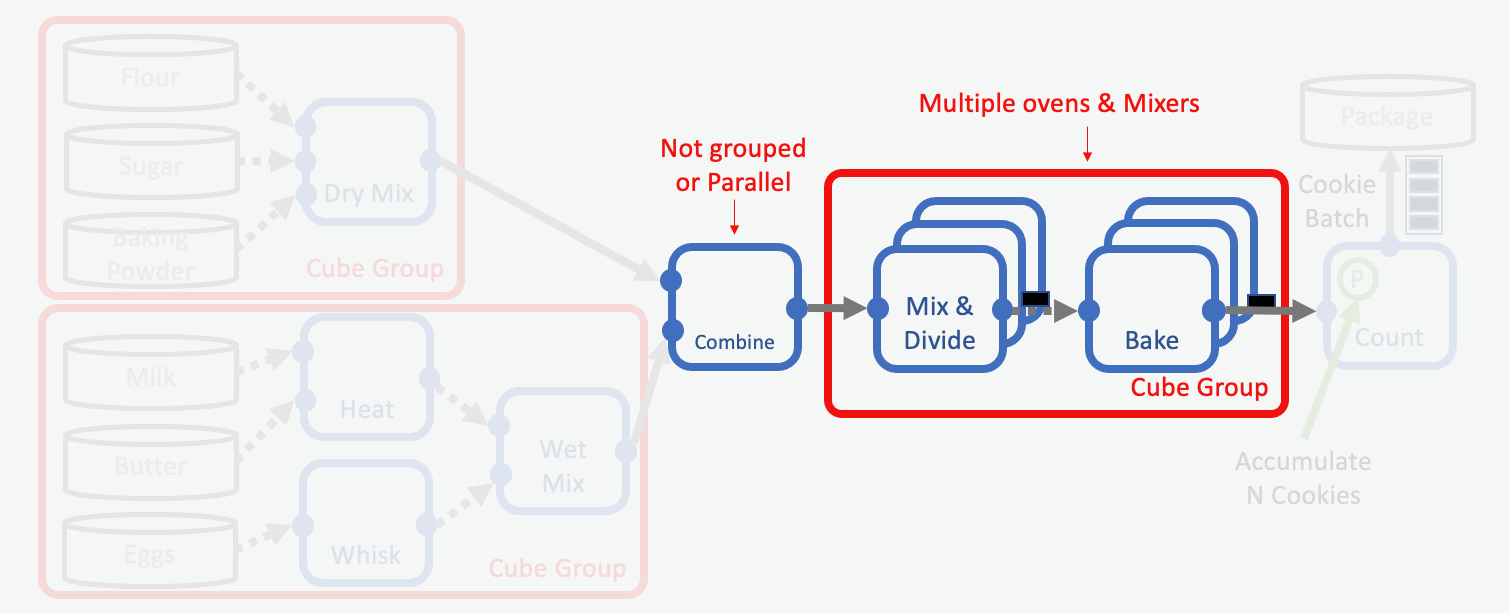
In our cookie factory, the mixing and baking processes fulfill all these criteria. We can use parallel cubes for these steps, and we can place these cubes in a parallel cube group to reduce serialization costs.
In order to do that, we need to introduce a serial cube first which combines the outputs of the WetMix and DryMix subfloes. This cube ensures that we get the proper ratio of wet and dry mix for making the unbaked cookies. Since this is a bookkeeping problem the merging cube itself cannot be parallelized, but its output can be processed in parallel.
When Not to Parallelize
Parallelization can be a very useful tool to alleviate bottlenecks caused by slow cubes. However, parallelization is not a one-solution-fits-all fix. There are several cases in which parallelization is not the best solution to a problem. The responsibility of the developer is to use parallel cubes when needed but not inappropriately. Parallel cubes should not be used:
When the task does not scale with the number of input records. Parallel cubes will run one manager and n worker EC2 instances. This means that if the task is very small, and it does not scale with the number of inputs the cube is receiving, the scheduler has to assign two EC2 instances where one would be sufficient. The scheduling time for the EC2 instances may cancel out any benefit from parallelization because the task would finish before the scheduler has time to scale up the calculation.
When performing very long calculations (*Without careful forethought*). Parallel cubes have a built-in time limit of 11.5 hours for one piece of work, since the calculation has to finish strictly within the 12 hour time limit set by AWS. Thus, if a parallel instance calculation exceeds this time limit, the cube will die, and Orion® will NOT automatically restart the cube. The records can still be emitted from the dead parallel worker cube using the parallel cube method
process_failed(). This means that for long parallel calculations, it is necessary to manually monitor the runtime of the cube and gracefully terminate it before the time limit. The cube can then emit a record with restart data to any down-stream cubes (or a cube cycle) in order to continue the calculation gracefully.When calculating global and ensemble properties. For example:
Counting the total number of cookies.
Determining the average cookie weight.
Pairing specific cookie ingredients/mixtures.
et cetera.
This is because parallel cube instances do not know which work went to which parallel worker, and they have no access to data in the different instances. Thus they individual instances are unable to calculate properties that depend on more than one datapoint.
When pairing data from different sources. The problem is called the bookkeeping problem. The problem is related to the fact that parallel cubes cannot control which data is assigned to which worker instance, thus some worker instances may not receive the right data for pairing, resulting in left over unpaired data.
When batching data. The problem is discussed in more detail here. Briefly, the problem is related to the way cubes emit their data when no more input is expected. A serial cube uses the
end()method whenever Orion®signals to it that all upstream cubes are closed, and the cube itself has processed all its inputs. At that point it is possible to emit data the serial cube may have stored internally via itsend()method. For parallel cubes, theend()method is called by each worker each time it has finished a work assignment from the manager instance. The amount of work that the manager assigns to each worker at a time can vary, and can not be controlled by the developer. This means that parallel cubes can not control when theend()method is called to emit leftover data, and thus can not control the batch size of items emitted.When downstream cubes cannot keep up with incoming data. The problem is discussed in more detail here. Completing a task really fast in parallel does not help if the downstream task becomes the bottleneck instead. This would only trade one bottleneck for another. If downstream cubes cannot keep up with the rapid speed of input from a parallel cube, they will request data slower than it becomes available. This in turn can cause the parallel cube to stall. An inability of a downstream cube to keep up with an upstream parallel cube could be caused by:
I/O limits for caching, reading and writing to disk. This cannot be fixed entirely by increasing memory because of swapping.
Upload/download limits due to internal or external network capacity.
Slow calculation speed.
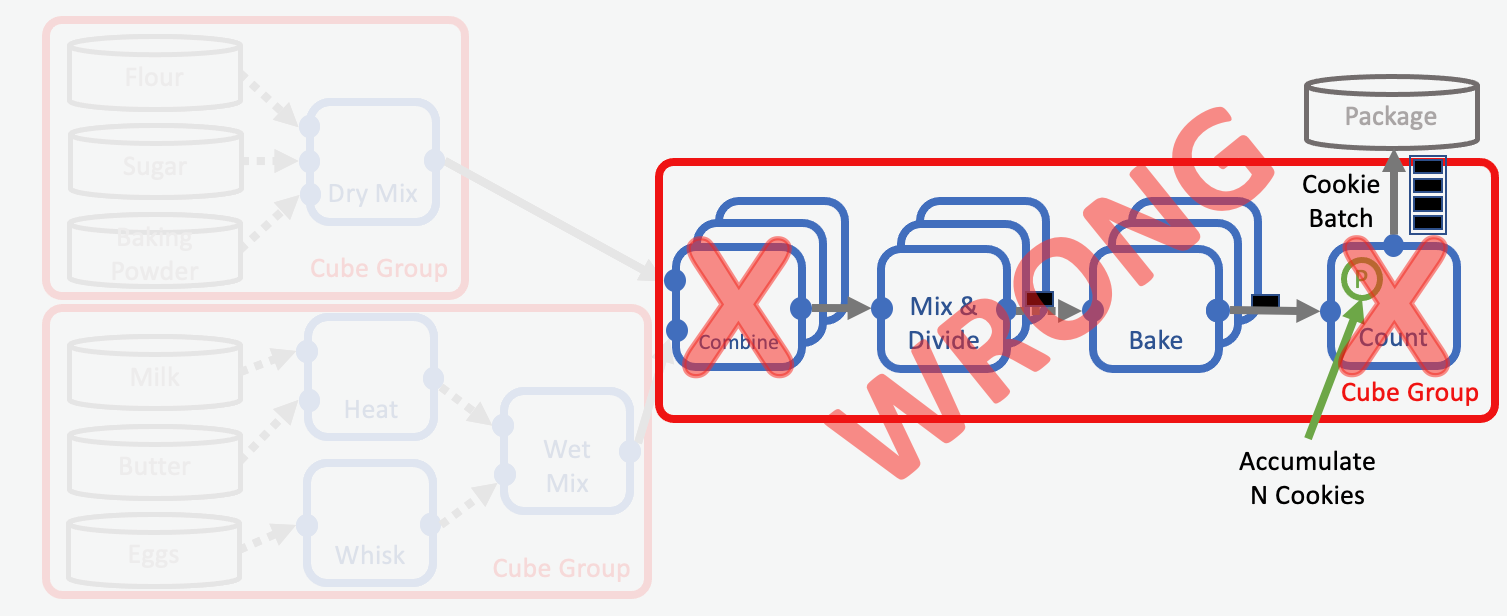
Impossible Parallelization. This floe is not functional.
We will use the above example floe to describe what is wrong with it:
Firstly, the Combine cube cannot be parallelized, since we cannot guarantee that each parallel instance gets the same amount of wet and dry mix to create an output with the desired ratio. This cube therefore has to be serial. Because we transform the cube to a serial cube it can no longer be put into a cube group with the other parallel cubes, as described here.
Secondly, the Counting Cube is a Serial cube and cannot be put in a cube group with Parallel cubes. This cube is also performing a global calculation (the counting of all the cookies), which cannot be performed in parallel. So the solution cannot be to convert the cube to a parallel cube in order to keep it in the cube group. This cube therefore has to be taken out of the parallel cube group.
For more details, see parallel cubes.
Parallel Cube Groups
In this section we want to give a brief outlook on how parallel cubes behave when placed in a parallel cube group. This allows for a better understanding of the proper use of parallel cube groups. Let’s say we have three parallel cubes A, B, and C that we want to put in a parallel cube group then:
A, B, and C will scale identically.
A, B, and C have the same number of parallel worker processes.
Scaling is prioritized (but not limited ) to the same EC2 instance.
Each worker of A is “paired” with workers of B and C of the same cube group, forming a crew of workers in a single instance.
Crew members use the same hardware, and has same hardware requirements.
Crew members are run on the same EC2 instance and in the same Docker image.
Crew members can access shared disk space, for example, a /scratch/ folder.
If A writes a file to /scratch/, its other crew members B and C can read the file.
B and C from a different crew however, cannot read the file.
The end() Method
In this section we want to discuss how work is distributed by the manager to
the parallel workers and how this influences the end() method. This knowledge is a
crucial part of understanding the difference between serial and parallel cubes.
A parallel worker is assigned items of work by its manager, and functions similarly
to a serial cube. The major difference is that while a serial cube terminates
when it finishes work, a parallel worker will instead signal to the manager
that it is ready for more work. As a consequence a serial cube will call the
end() method once at the end of its work. In comparison, a parallel cube worker
may call the end() method multiple times, each time it has finished
an assigned amount of work from the manager.
The manager assigns work to the workers and is in control of hiring (scaling up) and firing (scaling down) workers. Scaling is done automatically and depends on the amount of work that has to be done and the speed at which it is being done. The amount of work assigned to a worker is determined by the manager alone, and can not be controlled by the developer.
The amount of work that the manager sends to a worker, depends on how much work it has accumulated. The amount of accumulated work depends on the frequency that work arrives at the manager and the frequency it is requested by workers. Thus, it depends on worker speed and number of workers.
The item_count cube parameter determines the maximum amount of work that
the manager can assign to a worker at a time. As an example, if item_count
is 10, and the manager has more than 10 items buffered at the time of a work
request, 10 items will be sent to the worker. If the manager has less than
10 items, he sends all he has. The manager will never send 11 or more items
to a worker.
It is important to understand that because of this, the number of work items
received by the worker can vary. Since the end() method of a parallel
worker is called after all its current workload has been processed, the
end() method is called after a variable number of items. It should be
highlighted again, that this can not be controlled by the developer.
Therefore, it is best practice to not parallelize a serial cube that
uses the end() method to emit data. This is relevant for all situations
in which control of the end() method is needed, for example for
batching cubes.
While setting the item_count to 1 would give control of when end()
is called, this would would simply call end() every time process()
is called. In other words, any code in end() can be moved to process(),
making end() obsolete. Furthermore, setting the item_count cube
parameter to 1 will result in a lot of unnecessary overhead.
Since it is easy to extend a serial cube into a parallel cube, it is easy to overlook the potential consequences of this altered behavior.