Collections I/O
For most assembly lines, reading and storing data is crucial for the efficiency of the entire workflow. I/O operations come with a cost which (if possible) should be minimized. This is even more true for large amounts of data, for which it is best practise to use collections. This chapter will introduce you to basic concepts of performant collections I/O.
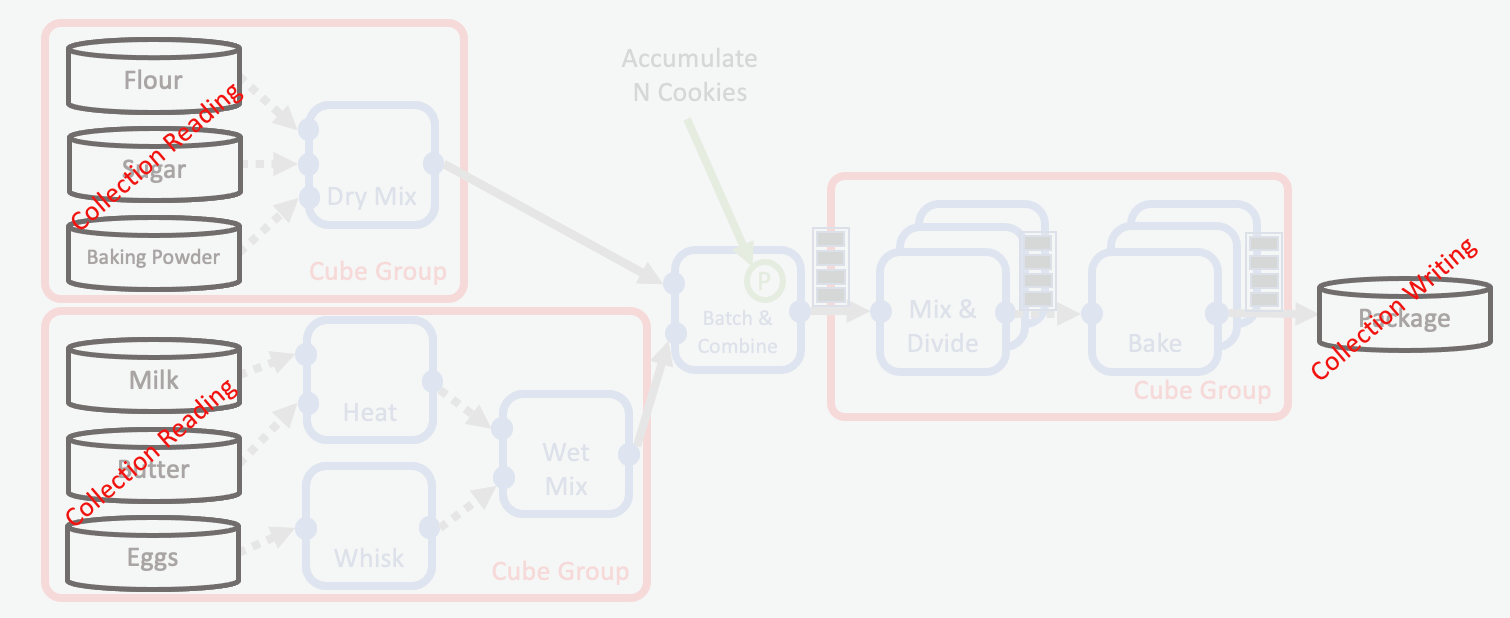
To recap: in Orion® collections are a data storage format composed of randomly accessible shards stored in S3. In our cookie making example, this is the equivalent of having ingredients and cookies stored in a warehouse from where they can be retrieved when needed.
Some characteristics of collections I/O in Orion®:
Larger boxes (shards) are heavier and slower to retrieve or store from/to storage.
In principle, shards are binary files that can store any kind of data.
When it comes to storing molecule data in Orion®, shards can be seen as a list of records.
In Orion® the number of items (records) can be used as an approximation of shard size. Because of differences due to molecule atom count and number of conformers of each molecule, this is only an approximation, but it is a useful one.
Shard storage has two main steps:
Putting items (records) into boxes (shards) that should be approximately equally full (batching).
Storing (uploading) the boxes (shards) in the warehouse (S3).
There are a few best practices that should be kept in mind when optimizing collections I/O:
Whenever possible, reading of data/shards should be parallelized.
Writing Shards, on the other hand, are preferred not to be done in parallel (details below).
Shards should be (roughly) of same size so that when reading them parallel workers take roughly the same time to download and process each shard.
Efficient Collections I/O
Reading Collections
Reading molecular data from a collection in S3 has two main steps:
Read shards from collection
Read records from shards
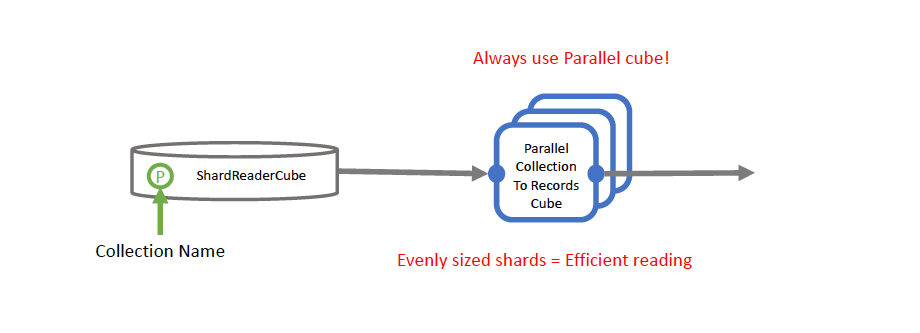
Reading Collection with a Shard Reader Cube
If the individual shards are approximately of same size, the parallel workers would take roughly the same time for downloading and processing them. Since shards in a collection can be randomly accessed, it is best practice to read them in parallel.
The following example shows how a collection can be read with an example cube ParallelExampleShardsToRecordsCube which is functionally equivalent to the standard Orion® cube ParallelCollectionToRecordsCube.
# (C) 2022 Cadence Design Systems, Inc. (Cadence)
# All rights reserved.
# TERMS FOR USE OF SAMPLE CODE The software below ("Sample Code") is
# provided to current licensees or subscribers of Cadence products or
# SaaS offerings (each a "Customer").
# Customer is hereby permitted to use, copy, and modify the Sample Code,
# subject to these terms. Cadence claims no rights to Customer's
# modifications. Modification of Sample Code is at Customer's sole and
# exclusive risk. Sample Code may require Customer to have a then
# current license or subscription to the applicable Cadence offering.
# THE SAMPLE CODE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
# EXPRESS OR IMPLIED. OPENEYE DISCLAIMS ALL WARRANTIES, INCLUDING, BUT
# NOT LIMITED TO, WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
# PARTICULAR PURPOSE AND NONINFRINGEMENT. In no event shall Cadence be
# liable for any damages or liability in connection with the Sample Code
# or its use.
from floe.api import WorkFloe
from orionplatform.cubes import ShardReaderCube
from advanced_cubes import (ParallelExampleShardsToRecordsCube,
LogWriterCube,
)
# Declare WorkFloe
job = WorkFloe("Collection Reading Example")
job.title = "Reading Collections"
job.description = "Example of printing Records to the log"
job.classification = [["Educational", "Example", "Cube Development", "I/O", "Record", "Shard", "Collection"]]
job.tags = ["Educational", "Example", "Cube Development", "I/O", "Record", "Shard", "Collection"]
# Declare Cubes
read_collection = ShardReaderCube("read_collection")
shards_to_records = ParallelExampleShardsToRecordsCube("shards_to_records")
logwriter = LogWriterCube()
# Promote/Override Parameters
read_collection.promote_parameter("collection",
promoted_name="collection")
# Add Cubes to WorkFloe
job.add_cubes(read_collection, shards_to_records, logwriter)
# Connect Cubes
read_collection.success.connect(shards_to_records.intake)
shards_to_records.success.connect(logwriter.intake)
if __name__ == "__main__":
job.run()
Writing Collections
Writing collections in Orion® has the following steps:
Create an empty collection.
Batch records for approximately equal Shard sizes.
Write record batches to files.
Upload files as Shards to S3.
Close Shards.
Close Collection.
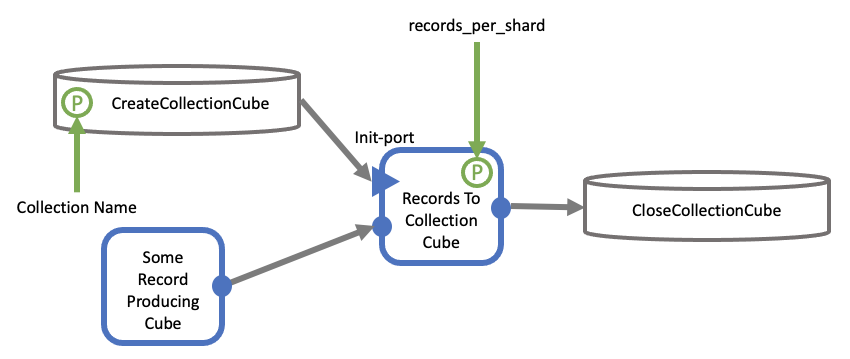
Writing a Collection with the RecordsToCollectionCube
As stated earlier, efficient collection reading demands the shard sizes to be similar in size. We will introduce an implementation of how to achieve balanced sizes by batching incoming records in the Shard writer, thus enabling us to write a desired number of records into each shard.
Note
It is essential not to use a parallel cube in this case, due to the fact that batching should not be done in parallel because of how parallel cubes are unable to control batch size.
Note
It is important to select an appropriate value for the records_per_shard
parameter of the writer cube. This is because the default of the parameter
is 1, leading to “single record shards” that might create an expensive
overhead for writing as well as reading the collection.
Serial Writing
Writing collections in serial is the same as metaphorically having a single worker at the cookie factory doing two jobs:
Evenly distribute (batching) the items (records) into boxes (shards)
When a box (shard) is full, store (upload) it in the warehouse (S3)
The following example floe is the recommended way for creating record balanced collections. The floe makes use of the standard Orion® cube RecordsToCollectionCube.
collection_writing_basic_example_floe.py
In Orion®, the recommended way for batching and uploading is the serial cube:
RecordsToCollectionCube. This cube has a key parameter records_per_shard,
which determines the number of records it puts in a single shard before
uploading it to S3.
Closing a Collection
Once all the shards have been written to S3, it is required to ensure that all of them are closed. After that, the collection itself needs to be closed. This marks the collection as ready for use. These concluding steps have to happen strictly downstream of the writer cube to avoid data duplication in case of writer failure and restart. Therefore, a close collection cube cannot be in a cube group with any collection writing cube, as that would mean it is not strictly downstream of the writing cube. Thus, the best practices for closing a collection are:
Closing of the collection must happen downstream of the writing cube.
A close collection cube cannot be put in a cube group with a writing cube.
Note
It is best practice to ensure that you are actually uploading data to the shard. Otherwise a shard would be closed immediately after its creation, resulting in empty shards that cannot be downloaded.
Advanced Writing
Compared to serial writing, parallel writing to collections in Orion®is the same as a team of workers working together, where:
One worker distributes (batching) items into boxes (shards).
Many workers store the boxes (shards) when they are full (upload to S3).
An advanced floe for writing to collections could look like this:
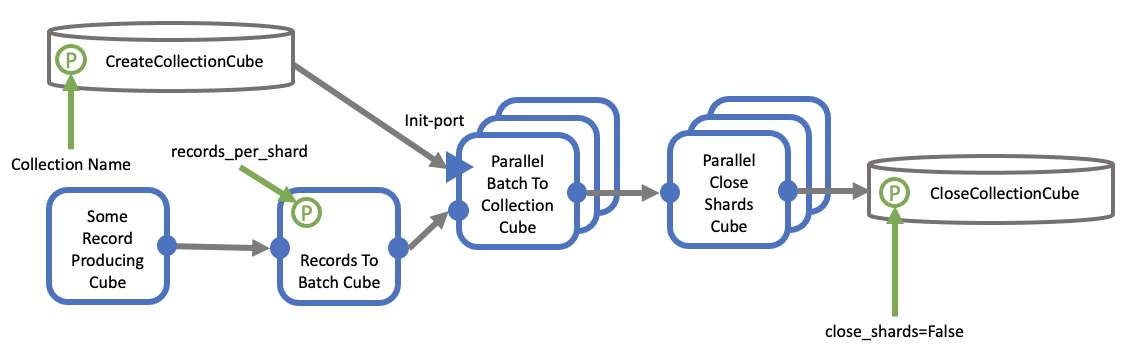
Writing a Collection with Parallel Cubes
Batching has to be done in serial because of how parallel cubes are unable
to control batch size. Batch size cannot be controlled in parallel because
of the behavior of the end() method for parallel cubes.
Nevertheless, the upload itself can happen in parallel, potentially improving
the performance of the overall collection writing. However, the selection of
the right batch size is relevant for the performance, as illustrated in this
graph:
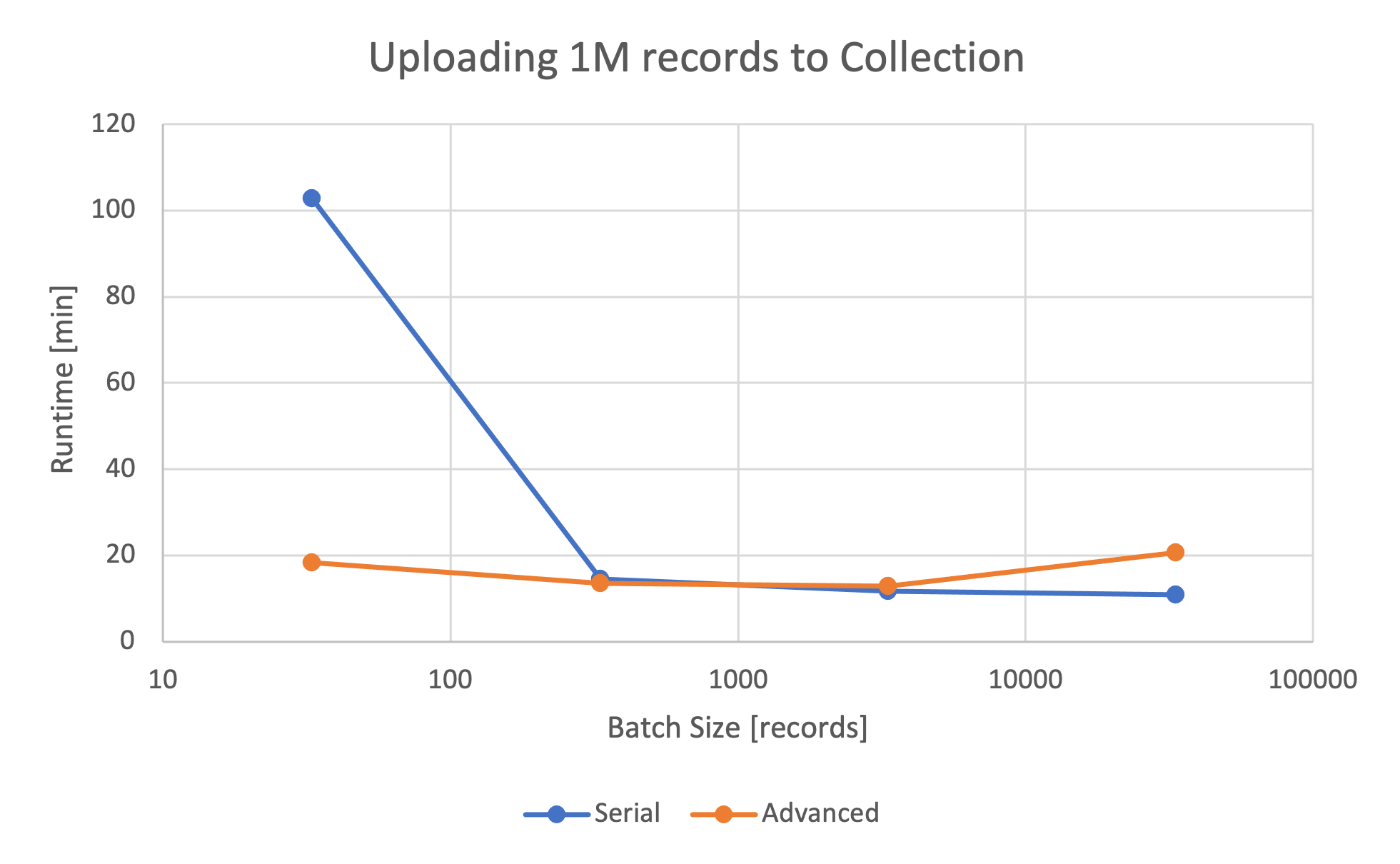
Runtimes of Simple and Advanced Writing
We can see that the performance of parallel collection writing scales inversely with the selected batch size:
Small batch size: Up to 5 times faster than serial writing because of parallel shard upload.
Big batch size: Comparable or slightly slower than serial writing (because of more cubes and less chance to scale).
Benchmarking the runtime of the simple and advanced floes reveals that there can be a benefit to parallel writing depending on the batch size.
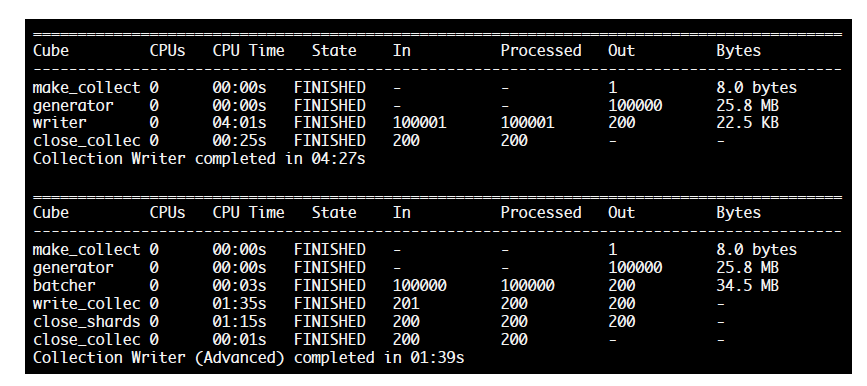
Comparison of Simple and Advanced Collection Writing (Batch size=500)
An example of an advanced collection writing floe used above can be downloaded here:
Conclusion
Reading collections should be done using a parallel cube that:
Reads shards from a collection.
Reads records from the shards.
Writing collections, can be done either in serial or with an advanced floe, depending on the later usage of the collection:
Serial
Easy to implement.
Good for large batch/shard sizes.
More downstream idle time.
Advanced
More work to implement, more cubes.
Good for most batch/shard sizes.
Less downstream idle time.