Concurrency
In floe design, if possible, we want to avoid the situation in which downstream cubes need to wait for an upstream cube to finish processing its data. It is advantageous if cubes can run concurrently to reduce the overall runtime of the floe. In our cookie making example, the DryMix cube does not need to wait until the WetMix cube finishes its work. These two tasks can be performed independent of each other.
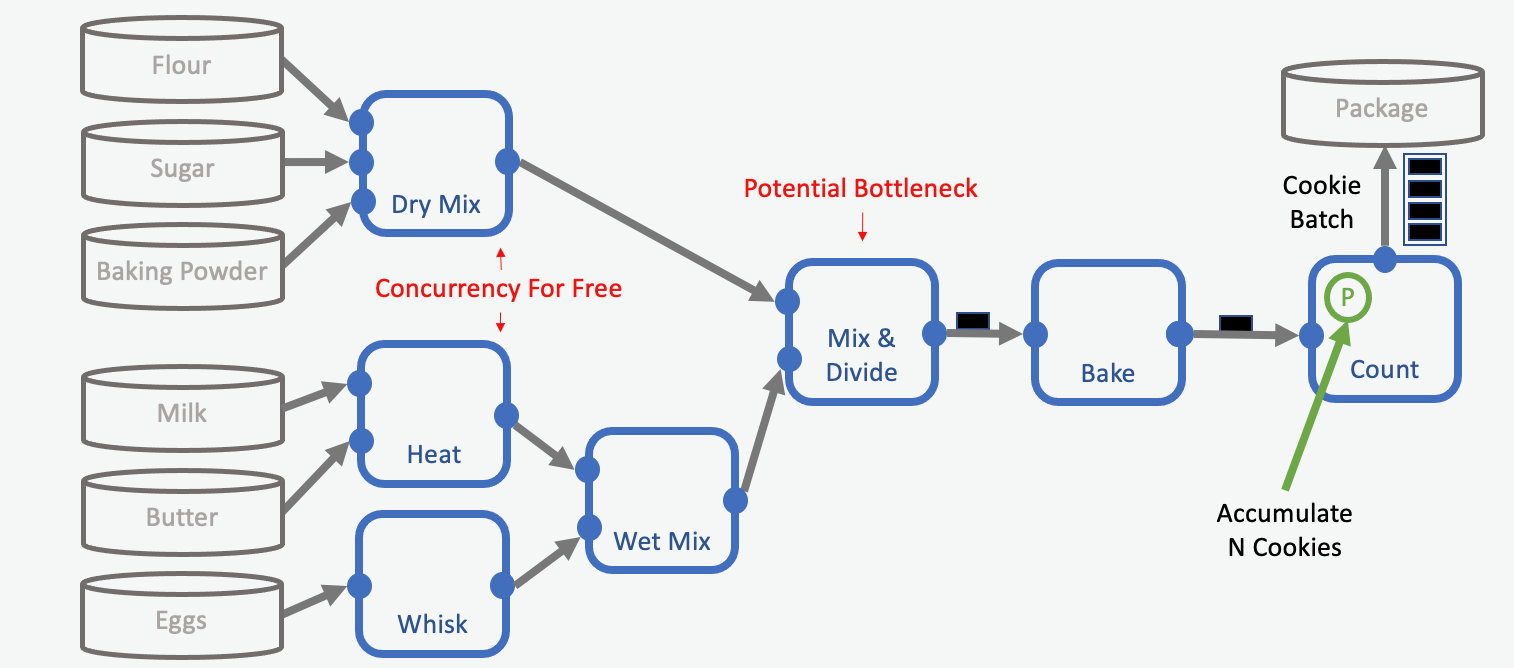
Possible Concurrency in the Process. The input parameter (P) specified the number of cookies (N) to accumulate.
Our objective is to minimize the total runtime of the cookie making process. Independent tasks that can run at the same time can be modeled as separate subfloes. Notice the characteristics of such concurrent subfloes:
They are using (reading) independent ingredients (data sources, i.e. Datasets, Files, Collections).
They are performing different functions.
They can pass their output (results) to a receiving station, in our example the Mix & Divide station. The receiving station has multiple input ports to handle input from different subfloes.
The rate limiting step is the processing speed of the slowest upstream subfloe.
In our cookie making example, the processing speed of the Mix & Divide station is dominated by the output speed of the more complex upstream WetMix subfloe. This is because Mix & Divide station combines the prepared wet and dry mixes in a 1:1 ratio and the WetMix is the slower subfloe. It is best practice to take care that the output-rate of subfloes are similar when combining them.
The Bottleneck problem - Why Do Cubes Stall?
In this section we want to give a brief outlook on how data is transferred between cubes in Orion®. This is relevant to understand several problems developers may run into, especially when it comes to merging results from different sources. In Orion®, a cube will request data from upstream cubes when two basic conditions are met:
The cube is not busy processing the data that it already has.
The cube is not already buffering as much data as it can.
Upstream cubes will only send data downstream when they receive a data request from a downstream cube. If the downstream cube is slow, it requests data less frequently. If at the same time the upstream cube is fast, it produces data more quickly than is requested by the slow downstream cube, which results in a bottleneck.
When a bottleneck occurs, the upstream cube will temporarily store its output in an output buffer. When the output buffer is full, the cube stops processing new data and becomes idle. This is known as stalling. Stalling of a cube can potentially propagate upstream until all upstream cubes are stalling.
The size of the cube buffer is determined by the buffer_size cube parameter
and can be customized by the developer. Increasing the buffer size can help to
smooth out the flow of data in cases where a cube has periodic bursts of data.
However, this is not a fix for a bottleneck, since it does not address the cause
of the problem, which is the rate that downstream cubes request data.
A bottleneck can happen for several reasons: One reason is that the cube processes its input slowly and requests data infrequently. Another reason is that the cube needs to merge inputs from different sources coming in at different rates, and has to wait for the required data to be paired. In the latter case, the cube may need to store large amounts of data in memory to perform the pairing. Therefore, if a cube needs to pair data from different sources, it is important to take care that it has sufficient memory available.
Sometimes we have to live with the fact that we have a slow and a fast subfloe. When this is the case we have to live with the potential idle time of upstream cubes. However, there are approaches for how to optimize slow subfloes, as discussed here.
The Bookkeeping Problem - How to merge output of subfloes
There are two ways to merge data from different subfloes:
If one specific output of a subfloe needs to be combined with another specific output of a different subfloe, it is necessary to store data internally (only) until its counterpart has been found. This is called the bookkeeping problem and requires a serial cube. Parallel merging is not possible, because parallel cubes can not control which data is sent to which worker, so data may not be paired because it was sent to different workers.
In our cookie making example, because wet and dry mixes are from different sources, and come in large quantities, merging in the Mix & Divide station cannot be done in parallel. If the Mix & Divide station in our cookie example was parallelized, some workers might not get the right counterpart ingredients they need to make a cookie, and would end up with unused resources left over because the ingredients they needed were sent to a different worker.
If data needs to be combined in general, and do no require item-specific pairing, it can be done in parallel by using an init port for one of the data sources.
An example of general merging could be to merge a short list of queries with shards containing molecules for comparison. In this case, the use of an init port for the queries sends copies of the queries to all workers. This is only useful when the amount of data received through the init port is small and the pairing is all-vs-all, i.e. all shards are paired with all queries. If the amount of data is large, the cost of copying and sending data to all workers cancel out the benefit of parallel pairing. General pairing is useful because it can be done in parallel since it does not need to keep track of which data is paired with which.
To summarize the bookkeeping problem, it is important to keep in mind that:
Merging can be a bottleneck which may cause stalling.
Parallelization of a merging cube is not possible when pairing specific data from different sources.
For example, pairing molecule structures with assay data via their molecule titles.
Parallelization of merging is only possible when items do not require a specific counterpart for pairing.
For example, pairing a list of queries with database Shards for subsequent molecule comparison.