Data Traffic
It is not always possible to eliminate traffic by simply placing different stations of the assembly line in the same building (cube group). Our cookie factory will at some point have to deal with the transport of cookies or ingredients (data) from one building to another. This transport comes with costs which are serialization and overhead.
In general, these costs depend on:
The size of the item(s) transported.
The number of items sent at a time (buffer, batch).
In our cookie factory, items are sent through gates (ports) which are specific to the item type.
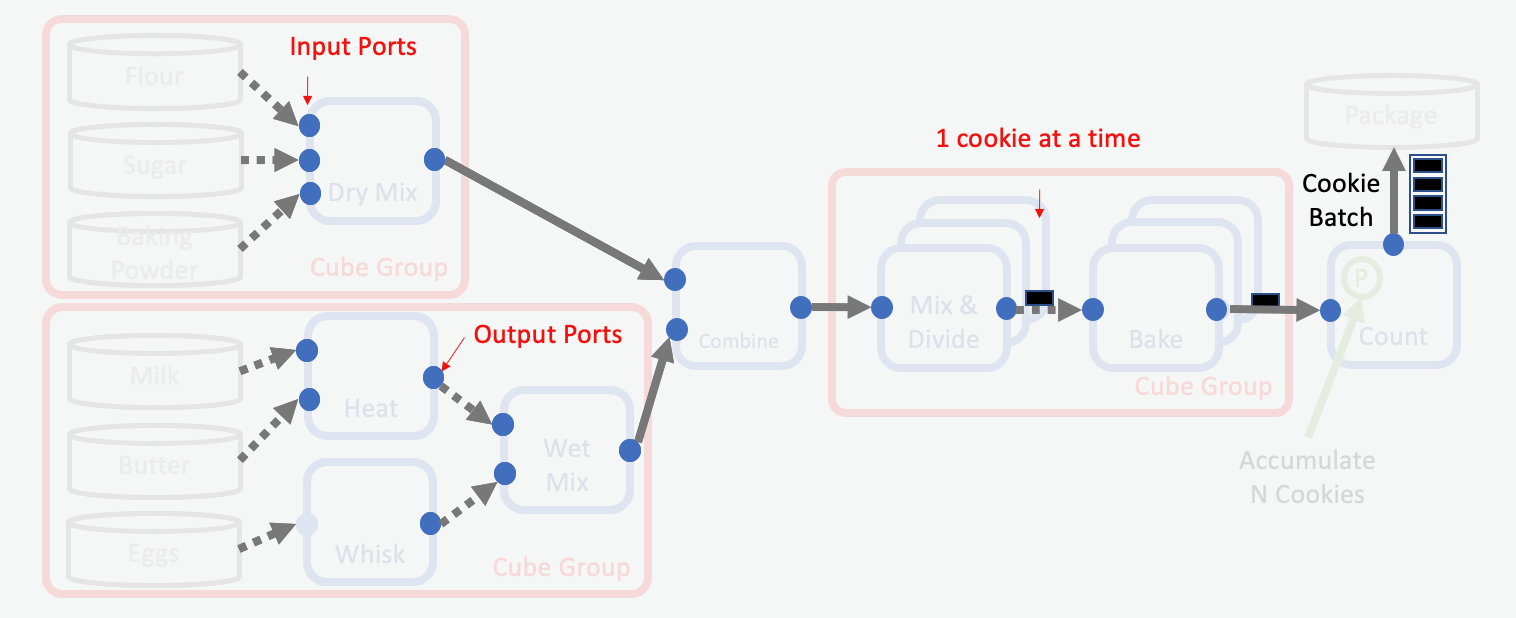
Transporting Ingredients and Cookies (Data). Dotted lines reflect that no serialization of the data is required
The goal is to make transportation at the cookie factory as efficient as possible. There are a couple of best practices one should adhere to in order to reach that goal:
Put only necessary data in your records. This minimizes the overall amount of data required to be sent between cubes (or cube groups).
Use ShardInputPort and ShardOutputPort for sending/receiving shards. Shards are described in more detail here.
Use RecordInputPort and RecordOutputPort for almost everything else. This is preferred over using custom ports for other data types. The reason being that the input and output ports for records have been optimized for serialization, while other ports have not. If you find RecordPorts to be a bottleneck, please contact OpenEye Support for help.
Records are the preferred packaging option in Orion®. As a reminder records can:
Contain other Records.
RecordVec (Batching).
Contain other data objects.
Lists (FloatVec, IntegerVec).
Strings.
Blobs.
Optimizing Data Traffic
For our cookie making factory, we want to optimize the Mix & Divide and Baking stations by using batches. We do so by modifying the Combine Cube to accumulate a batch of cookie ingredients before sending it downstream. After this change, instead of mixing ingredients for one cookie at a time, the Mix & Divide cube can mix the ingredients for an entire batch of cookies at once and will send the cookie dough for an entire batch of cookies downstream. Now the Bake cube can bake a batch of cookies at once and send an entire batch of baked cookies downstream. The final storage is also simpler, since an entire batch of cookies finish at the same time. They can be packaged at once instead of waiting and accumulating individual cookies before packaging and storing. With these changes, our optimized assembly line looks like this:
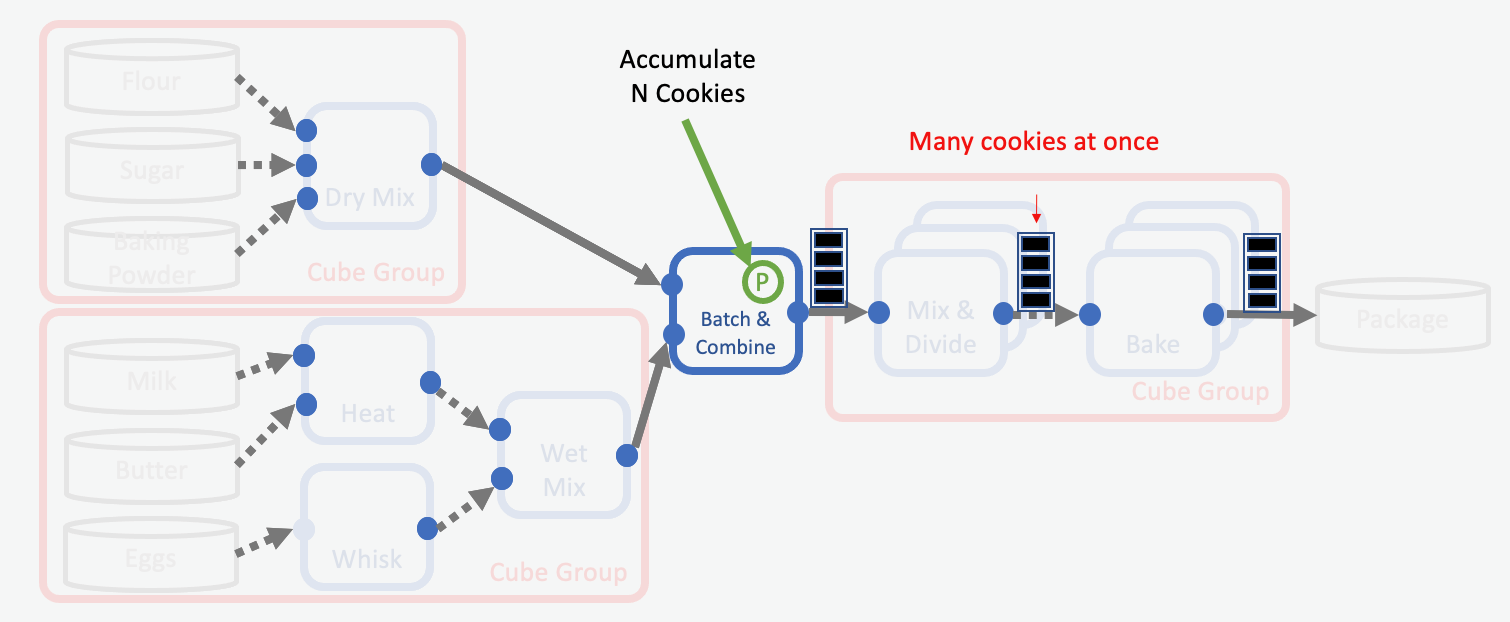
Optimization Using Batches of Cookies
Buffering and Batching
One crucial parameter for performant cookie transportation is the number of cookies sent at a time between buildings (cubes or cube groups). Sending single cookie takes more packaging (serialization) and causes a lot of traffic on the network. However, while sending many cookies at a time saves on packaging, the downstream cube might have to wait a long time until it receives any input, causing potentially unnecessary idle time. Finding the right balance depends on:
The processing speed of the downstream cube.
The way downstream processing is done.
Does downstream processing happen in batches (for example, writing to disk)?
Is there a bottleneck?
When deciding the number of items sent at a time it is best practice to keep downstream cubes in mind. There are two ways to bundle items before sending them downstream i.e. buffering and batching.
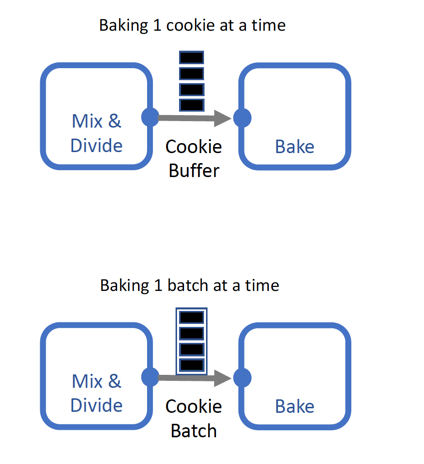
Buffering and Batching Cookies
Buffering
One way to decrease transportation cost is buffering. Each item a cube processes
is accumulated at the output port in an output buffer.
When a cube receives a data request from downstream cube(s), it will send a certain
number of items, say N, simultaneously. This number of items is specified by the cube
parameter item_count. In our cookie factory example, buffering is equivalent to
the upstream cube sending N delivery persons at a time whenever an order for cookie
ingredients arrives from a downstream cube. Each delivery person carries 1 item.
Buffering has the following characteristics:
It is implemented as a default in every port.
Buffer
item_countcan be easily adjusted as a cube parameter.Buffering lowers the number of data requests.
Downstream processing happens on a per item basis (No unpacking of batches into individual items is needed).
Batching
Another way to save on transportation is batching. Basically, each item is accumulated just like during buffering, but they are put inside a box which is sent and potentially unpacked into individual items at the destination. In our cookie factory example, batching is equivalent to the upstream cube sending one delivery person carrying N items in a box whenever a data request arrives from a downstream cube.
Batching has the following characteristics:
It is specific to the output data format and thus needs to be manually implemented.
Most of the time batches can be implemented as records with specific fields:
Types.RecordVec (No Data compression!)
Types.String
Types.FloatVec
Downstream cube processes the items in batches (for example writing to disk). If the downstream cube needs to process the items individually, batches need to be unpacked to access each item.
Batching allows for fewer records to be sent, which stresses the database less and can be significantly faster.
Batching is most effective when combined with saving data transportation cost.
Using Collections for Batching
Batching of records can be done with other records or with shards in collections. Using shards for batching, however, comes with additional cost that should be considered:
Converting records to shards and shards to records.
Uploading and downloading to and from S3.
If you have very large amounts of data that needs to be used in a cube far downstream of the data generation, it can be beneficial to store the data temporarily in shards and read the data downstream later on. This allows the link to the shards to be sent downstream instead of the shard content.
Buffering vs. Batching
When deciding if you want to use buffering versus batching, there are a few things to keep in mind:
Buffering:
Hits the database once per record, but does not compress any data.
Default
buffer_sizeof 2GB → Then stalling starts.Larger records fill up the buffer faster.
Batching:
Decreases the number of records.
Sends less number of calls to the database.
Works better if record size is reduced by removing the unnecessary data.
May need unpacking at the downstream cube, depending on the use case.
Optimizing Size of Buffer or Batch Size
When choosing the buffer or batch size, it is important to keep in mind that both small and large sizes have benefits. Optimal performance is obtained when the size is chosen carefully. A few things to consider:
Slow upstream cube.
Slowly fills up batch/buffer thus data is available less frequently.
Prefers small batch size to increase frequency of data availability.
Quick upstream cube.
Quickly fills up batch/buffer thus data is available more frequently.
Prefers large batch size to save on transportation cost.
Slow downstream cube.
Requests data less often.
Performance is less dependent on the rate at which input data is available upstream.
Quick downstream cube.
Requests data more often.
Performance is highly dependent on the rate at which input data is available upstream.
The overall best practices for choosing the size of the batch/buffer can be summarized as:
When the upstream cube is slow or when the downstream cube is fast, a small batch size is recommended to reduce the idle time of the downstream cube.
When the upstream cube is fast and the downstream cube is slow, a large batch size is recommended to reduce transportation cost.
To give some perspective: Small buffer/batch sizes are in the range of 10s-100s data items and large buffer/batch sizes are in the range of 100s-1000s data items. This is assuming that you are dealing with small data items such as common drug-like molecules.
Batching Example
To conclude this chapter, we want to give an implementation of a possible batching approach. As stated earlier, batching has to be manually implemented and is highly dependent on the use case. The code example below can be used as a starting point for understanding how to implement batching. The example also illustrates how the choice of batch size can influence the runtime of a floe. In our example we consider the case of sending 100,000 cookies through a floe that checks cookie quality.
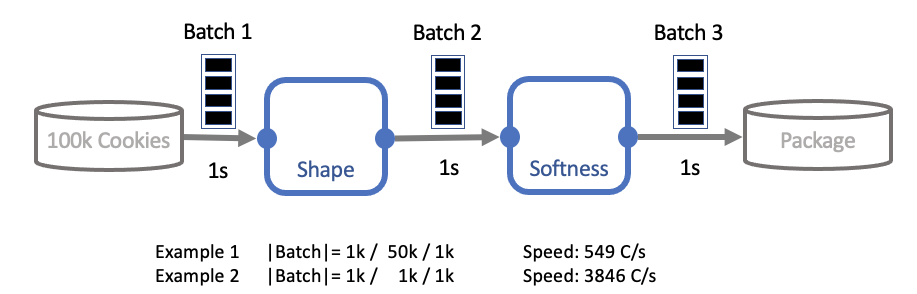
Example: Checking the quality of 100,000 Cookies
Code Example
# (C) 2022 Cadence Design Systems, Inc. (Cadence)
# All rights reserved.
# TERMS FOR USE OF SAMPLE CODE The software below ("Sample Code") is
# provided to current licensees or subscribers of Cadence products or
# SaaS offerings (each a "Customer").
# Customer is hereby permitted to use, copy, and modify the Sample Code,
# subject to these terms. Cadence claims no rights to Customer's
# modifications. Modification of Sample Code is at Customer's sole and
# exclusive risk. Sample Code may require Customer to have a then
# current license or subscription to the applicable Cadence offering.
# THE SAMPLE CODE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
# EXPRESS OR IMPLIED. OPENEYE DISCLAIMS ALL WARRANTIES, INCLUDING, BUT
# NOT LIMITED TO, WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
# PARTICULAR PURPOSE AND NONINFRINGEMENT. In no event shall Cadence be
# liable for any damages or liability in connection with the Sample Code
# or its use.
from advanced_cubes import (RandomMolRecordGeneratorCube,
RecordsToBatchesCube,
ResizeBatchesCube,
BatchesToRecordsCube,
)
from floe.api import WorkFloe
# Declare WorkFloe
job = WorkFloe("Batching Effect Example")
job.title = "Batching Effect Example"
job.description = "Example of how managing batch size can influence performance"
job.classification = [["Educational", "Example", "Cube Development", "Batches"]]
job.tags = ["Educational", "Example", "Cube Development", "Batches"]
# Declare Cubes
generator = RandomMolRecordGeneratorCube("generator")
batcher1 = RecordsToBatchesCube("batcher1")
batcher2 = ResizeBatchesCube("batcher2")
batcher3 = ResizeBatchesCube("batcher3")
decoder = BatchesToRecordsCube("recorder")
# Add Cubes to WorkFloe
job.add_cubes(generator, batcher1, batcher2, batcher3, decoder)
# Promote Parameters
generator.promote_parameter("record_number",
promoted_name="record_number",
default=100000)
batcher1.promote_parameter("records_per_batch",
promoted_name="batch_size_1",
default=1000)
batcher2.promote_parameter("records_per_batch",
promoted_name="batch_size_2")
batcher3.promote_parameter("records_per_batch",
promoted_name="batch_size_3",
default=1000)
# Connect Cubes
generator.success.connect(batcher1.intake)
batcher1.success.connect(batcher2.intake)
batcher2.success.connect(batcher3.intake)
batcher3.success.connect(decoder.intake)
if __name__ == "__main__":
job.run()
record_batching_example_floe.py
We will run this floe with two different batch sizes:
Batch size selected too large.
A bad example is in which we set the batch size value of the middle batch (batch_size_2) to 50,000 cookies (half of all cookies). This creates a bottleneck in the middle of the floe, because of a long idle time for the downstream cube.
Batch size selected appropriately.
A good example is in which we set the batch size value of the middle batch (batch_size_2) to 1,000 cookies. Now the downstream cube does not need to wait for the upstream cube to accumulate cookies.
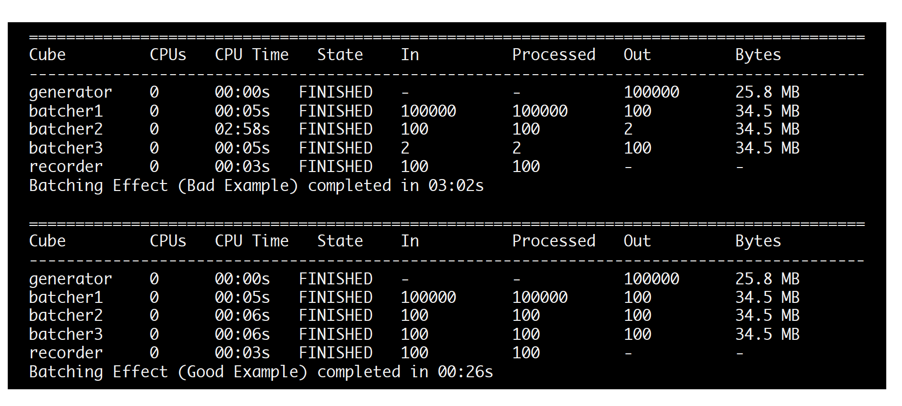
Comparing a Bad and a Good Example of Batching
When we run the examples we see that there is a difference in runtime. In real life, the optimal performance is not necessarily obtained by simply setting all batch sizes to the same value. Different cubes may run at different speeds, and therefore will fill up batches at different rates.