Clustering Tutorial¶
The Clustering Floes provide three ways for users to cluster molecules based on their 2D similarity. This tutorial describes the basic process for generating fingerprints of molecules, clustering these molecules based on their 2D similarity matrix, and examining these results in the analyze page and floe report.
Floes used in this Tutorial¶
The floes used in this tutorial are:
Dataset Similarity – Fingerprint Generation
Dataset Similarity and Clustering – DBSCAN
Dataset Similarity and Clustering – Hierarchical
Dataset Similarity and Clustering – Sphere Exclusion
Run the Fingerprint Generation Floe¶
To run the Fingerprint Generation Floe:
Open the Floe tab on Orion
Type “Fingerprint Generation” in the search box.
Click “Dataset Similarity – Fingerprint Generation” to open the Job Form.
Choose your input dataset, which must have a primary molecule field, and provide a name for your output dataset.
Specify one or more types of fingerprint from the dropdown menu provided in the Fingerprint Type parameter.
Run the floe.
Select a Clustering Floe To Use¶
There are currently three types of clustering supported in the OpenEye Cheminfo Floes. The following is only a basic comparison of the potential upsides or drawbacks to each method. Floe users are expected to do their own research and experimentation to determine which clustering method provided is most appropriate for their drug discovery application.
DBSCAN, Density-Based Spatial Clustering of Applications with Noise, is best for datasets that have arbitrary shaped clusters and outliers: datasets with lots of noise. However, it often results in very large and/or very small clusters.
Hierarchical clustering is useful when a set number of clusters is needed. However it is computationally expensive for large datasets.
Sphere exclusion clustering is an extremely simple and fast approach for clustering, good for large datasets. However, the number of clusters cannot be controlled.
Run the Selected Clustering Floe¶
Type the clustering method name (DBSCAN, Hierarchical, or Sphere Exclusion) in the search box.
Click “Dataset Similarity – <Clustering Name>” to open the Job Form.
Choose your input dataset, which must be one output from running the fingeprint generation floe of the previous step.
In the parameter “Fingerprint Field”, choose a field on your dataset that contains fingerprints. Fingerprint fields from the previous step will be prefixed with “fp_<Fingerprint Type>”.
Adjust cluster settings specific to your particular method as needed.
Clustering Floe Report¶
The clustering floe will provide a clustering report that gives a high-level overview of the data. This report will show the number of molecules in each cluster, and also provide an image of a representative molecule for each cluster. It will also show the clustering settings set by the user. Below is an example report. Clicking on an image of a representative molecule will allow you to view all the molecules in that cluster.
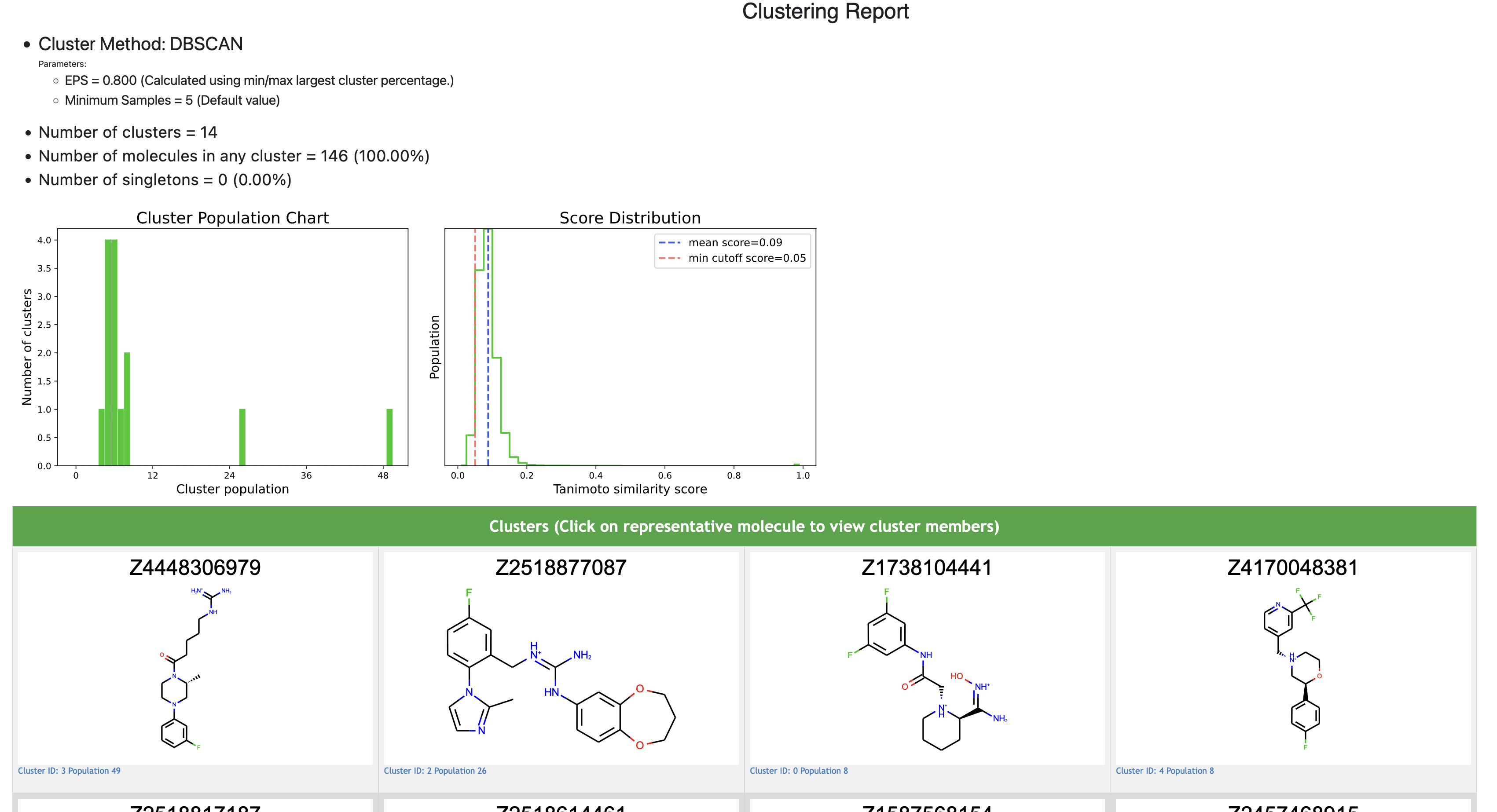
Clustering Report¶
View Cluster Data in the Analyze page¶
The following steps show how to analyze data further using the Orion analyze page:
From the JOB tab, click “Show in Project Data” next to the dataset named <Clustering Type> Members.
Click the + icon next to the dataset you wish to view in the Analyze page (Cores, Members, or Singletons). Cores will contain one representative molecule per cluster. Members will include all cluster members.
Click the Analyze tab in the left-most pane.
The Spreadsheet tab can be used to sort properties of the dataset, such as the Cluster ID.
The plot tab above the spreadsheet can be used to compare properties in a scatter plot, box plot, violin plot, or histogram. These plots unfortunately cannot plot cluster IDs. To analyze and plot based on a cluster ID, download the output dataset and retrieve the cluster ID field from each record to use in plots.
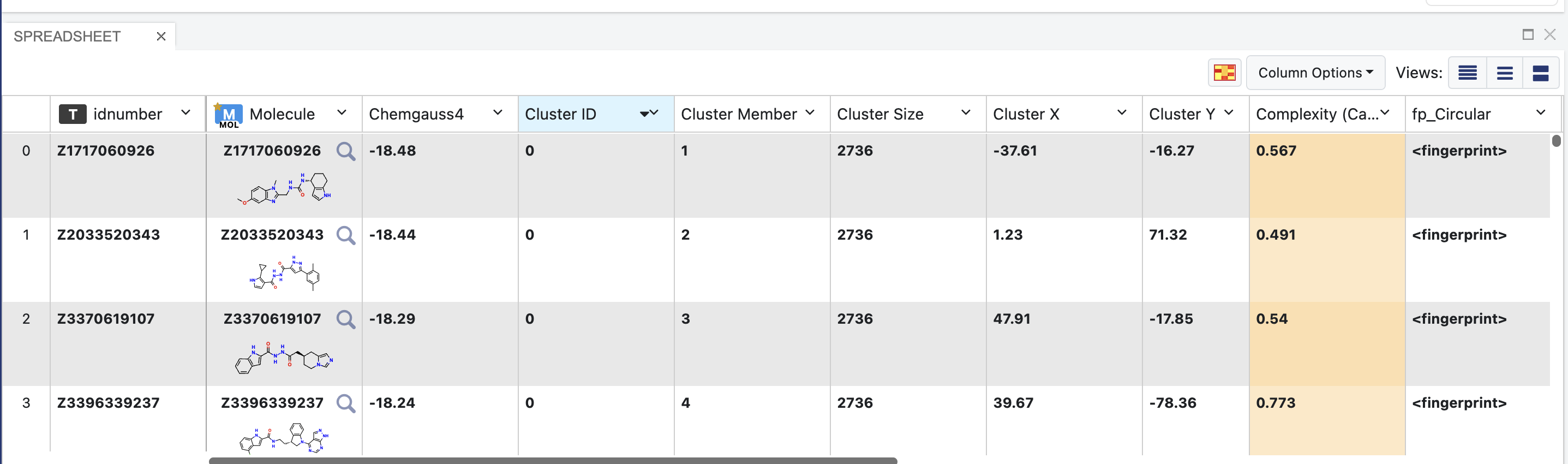
Spreadsheet of Cluster Members Output Dataset¶
View A Scatter Plot of the Clustering Data¶
In the plot tab above the spreadsheet, select “scatter” as the plot type.
For the X axis label, select Cluster X. For the Y axis label, select Cluster Y.
Select the Plot Options icon at the upper right of the plot. Then select the Color tab in this menu. Under Color dimension, select Cluster ID. Your scatter plot should now display a visualization of the data.
Other dimensions can be visualized by adjusting the size, color, or marker of points on the plot. Cluster ID cannot be visualized this way: please download output data for visualization of cluster ID.
To view specific clusters, select the Filters Tab at the top of the page, and filter by cluster ID. Select “Exact Match” and enter the ID of the cluster you wish to view.
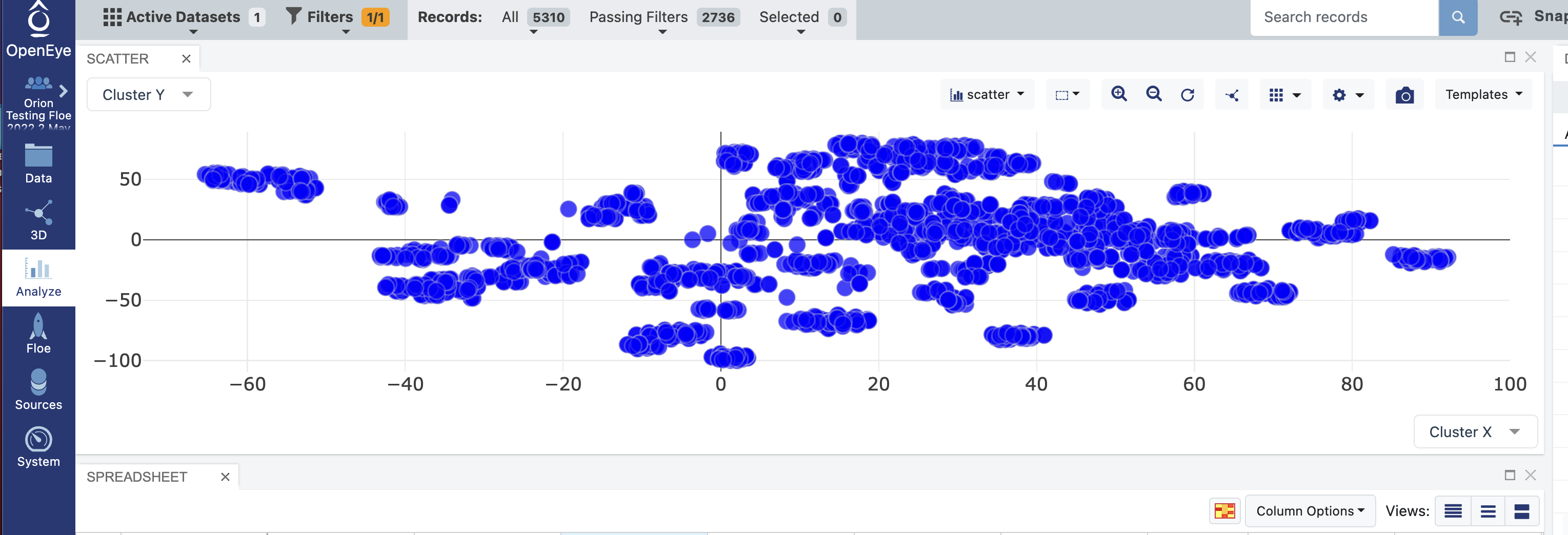
Scatter Plot of Single Cluster Selected through Filter¶