Release Highlights 2020.1
OEToolkits 2020.1.1
The OEToolkits 2020.1.1 is a bug-fix of the OEToolkits 2020.1 release.
OEToolkits 2020.1
The OEToolkits 2020.1 is a bug-fix of the OEToolkits 2020.0 release.
OEToolkits 2020.0
OpenEye Toolkits and Applications are now integrated into a single release cycle. This integration ensures that the tools delivered are more consistent across various product levels and, in keeping with OpenEye standards, are robust and efficient. In addition, the integration reduces release process management time, allows more time to deliver new features, and facilitates delivering bug-fix releases for critical issues when needed.
Omega TK: GPU-Omega - GPU-accelerated torsion driving
The 2020.0 release introduces GPU-Omega to the Omega TK.
GPU-Omega
provides accelerated torsion driving by utilizing a GPU (Graphics Processing Unit).
GPU-Omega is integrated into the existing Omega TK; no additional
user actions are required to make use of this new feature. GPU-Omega detects any
supported Nvidia GPU on Linux platforms and accelerates torsion driving automatically
unless explicitly suppressed through the option
OETorDriveOptions.SetUseGPU. GPU-Omega is available with
all sampling modes except macrocycle, which does not use the torsion driving
method for conformer generation. For more details on GPU-Omega, including prerequisites
and additional requirements for use with dense mode, please see
GPU-Omega.
GPU-Omega performs at the same high level of accuracy as Omega TK, as shown below using a filtered subset of the Platinum dataset [Friedrich-2017] [Hawkins-2020]:
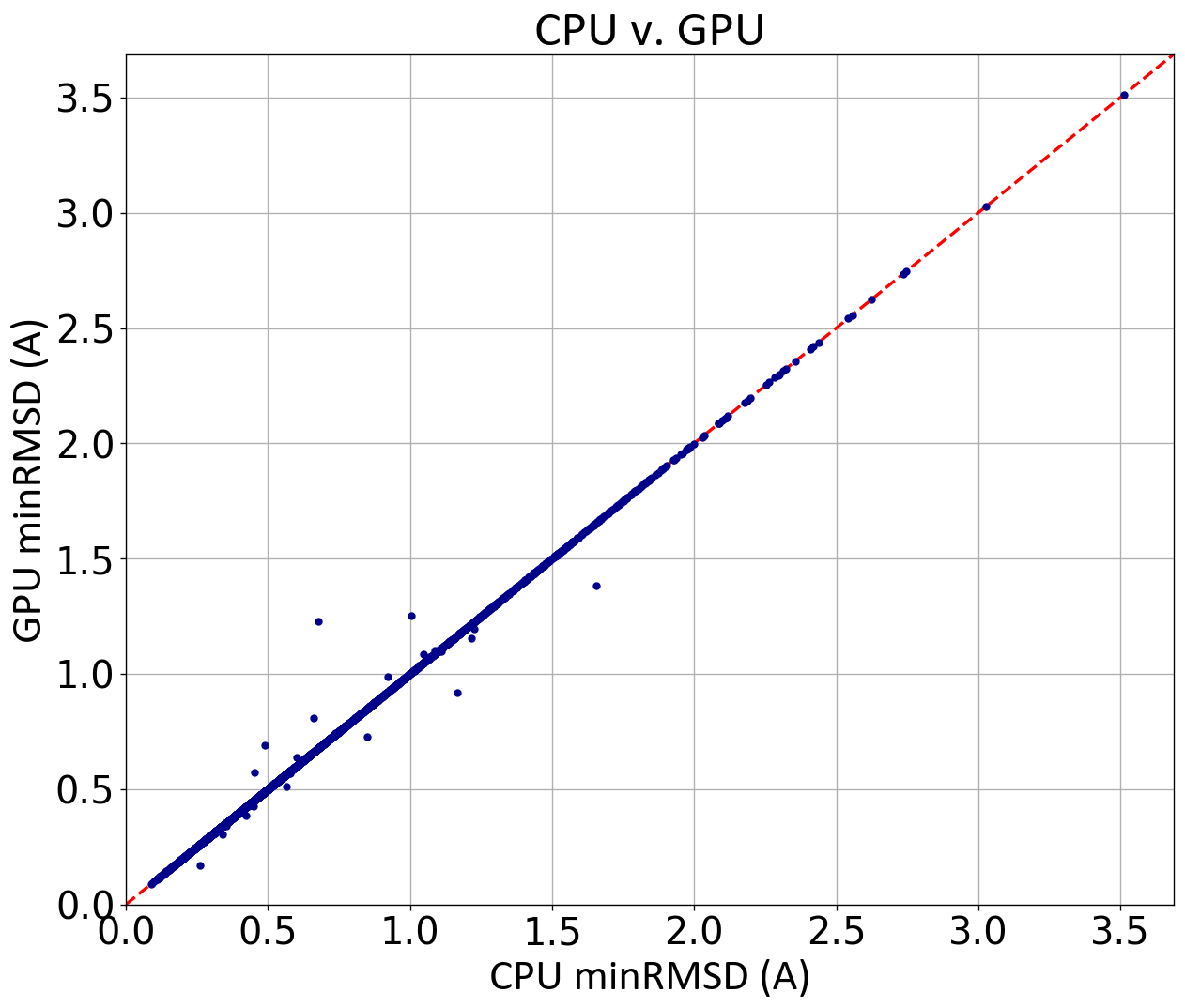
Comparison of the minimum RMSDs of CPU- and GPU-generated conformers against the experimental coordinates of a filtered subset of the Platinum dataset
GPU-Omega was benchmarked against the CPU on AWS to demonstrate the achievable
performance on a P3 instance,
which houses an Nvidia Tesla V100
GPU. GPU-Omega was benchmarked with all supported sampling modes (sparse, dense
pose, rocs, and fastrocs) using a subset of ~6000 molecules from the GSK TCAMs dataset
[Gamo-2010]. The most impressive speed-up is seen with the dense sampling mode, with
a reduction in time from 120 hours to less than 4 hours with GPU-Omega.
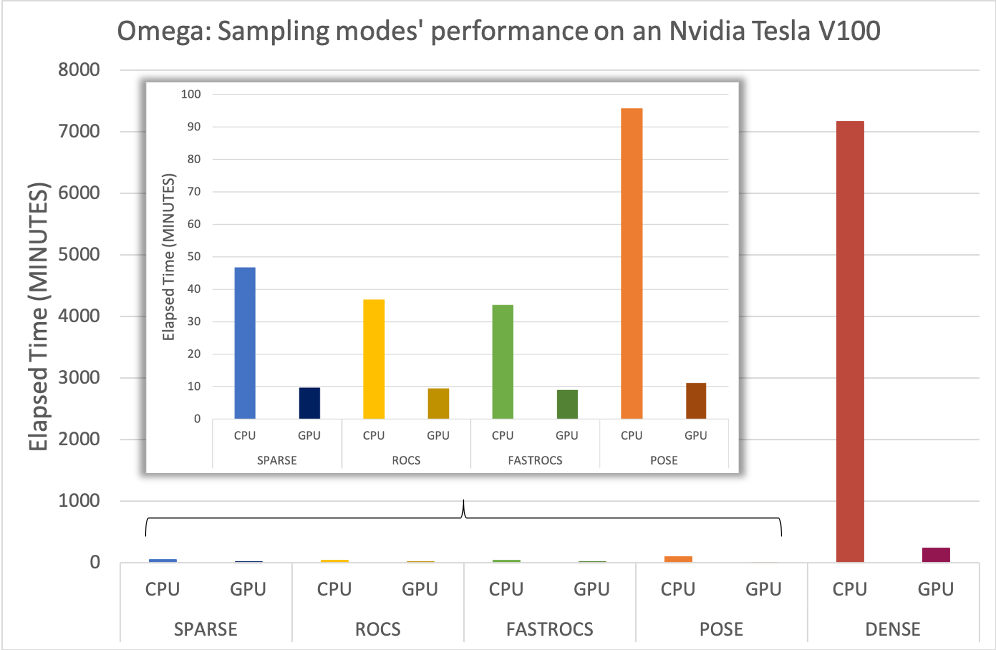
Elapsed time comparison between Omega and GPU-Omega on an AWS P3 instance when sampling a subset of the GSK-TCAMS dataset with sparse, rocs, fastrocs, pose, and dense modes.
FastROCS TK: Color optimization on GPU
Overlay optimization by color, in addition to shape, has been added to FastROCS. The color adds chemistry in the superposition and similarity analysis process, and thus facilitates identifying compounds that are similar both in shape and chemistry. FastROCS with color optimization was carried out on K80, M60, and V100 instances on AWS GPU instances and compared against those without color optimization:
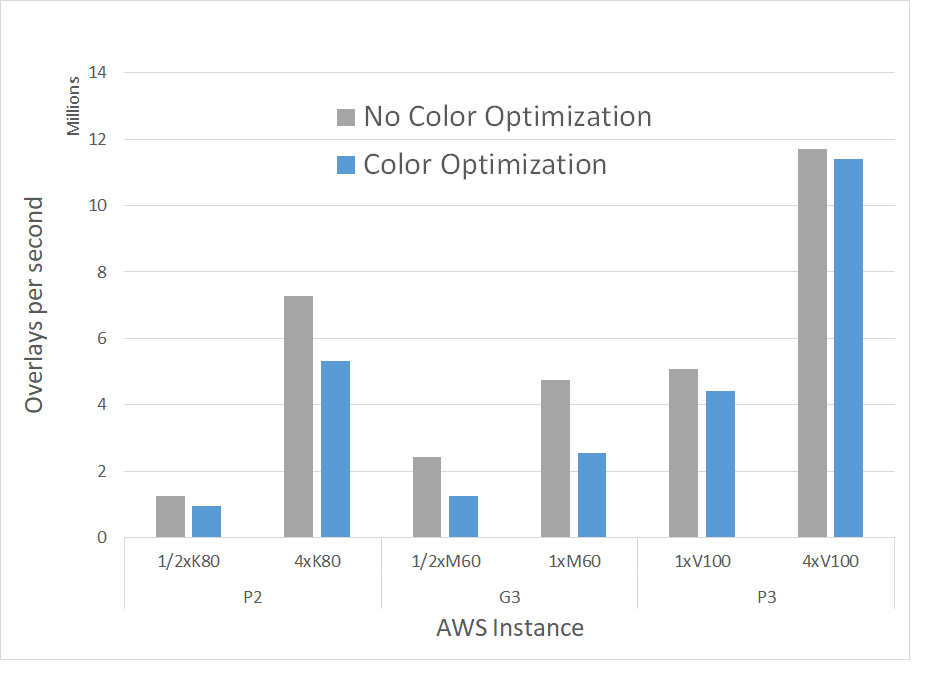
Performance comparison for FastROCS with and without color optimization in the 2020.0 release, using OpenEye’s standard benchmark dataset of 14M conformers on AWS.
Previous versions of FastROCS optimized over the shape score and followed that with a single point calculation for color. This can result in overlooking promising molecules. An example of the effect of optimizing over color and shape overlap rather than just shape overlap is shown below for XIAP BIR3 [Ndubaku-2009]:
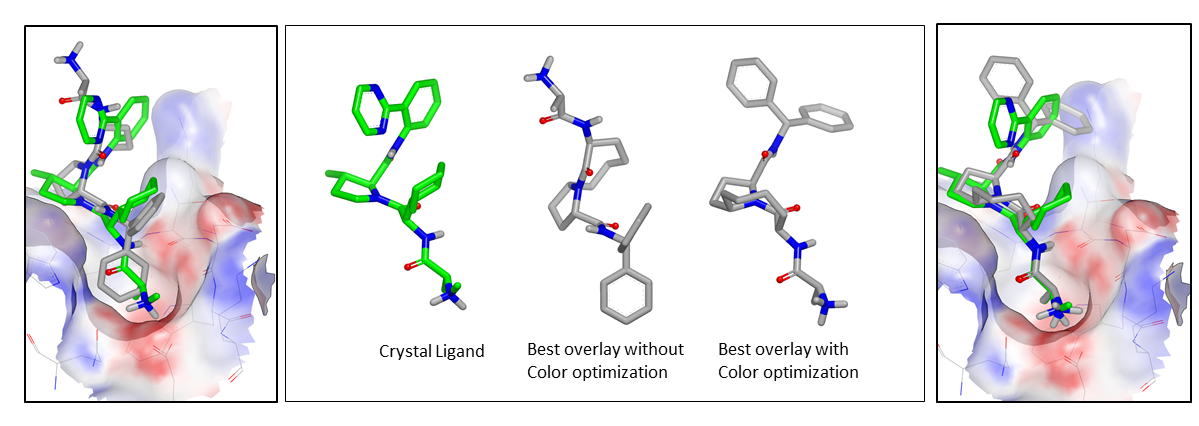
Example of the improvement using color optimization in FastROCS
On the far left is the XIAP BIR3 binding site with its crystallographic ligand in green. In the center is the crystallographic ligand, as well two copies of a known active ligand from the DUDE dataset [Mysinger-2012], with the best overlay from FastROCS without and with color optimization, respectively. Without color optimization, the ligand is not predicted to have high shape or chemical similarity. When color optimization is used, a high degree of chemical and volumetric overlap is predicted, as would be expected given that this compound is a known active. On the far right is the overlay in the binding site of XIAP BIR3, occupying a similar pose to the crystallographic ligand.
Spruce TK: Protein Loop Modeling
The 2020.0 release adds protein loop modeling to Spruce TK. This feature is
available with the lower level APIs OEBuildSingleLoop and
OEBuildLoops. It is also incorporated as an option
in the high level structure preparation API OEMakeDesignUnit.
The approach relies on a template database built from structures in the public RCSB Protein Data Bank. The database, which has been built for modeling loops that are 4-20 residues long by default, is available for download in a platform-independent format. An application in the SPRUCE bundle allows appending additional structures to the existing database. For example, proprietary in-house structures can be added, or the database can be completely rebuilt from scratch with different options.
This approach has been validated on a public dataset from Rossi et al. [Rossi-2007]. The results shown below were generated by building the excised loops back into the dataset, where the specific structures themselves were not part of the template database, and used the same success criterion as in the paper (<2.5A backbone RMSD). The results are generally good and the median RMSD is 0.6-0.7A (blue dots), irrespective of the length of the modeled loop. The unsuccessful cases (gray bar) have a large effect on the average RMSD (green dots), as loops are chosen that deviate significantly from the expected. Only in a single case of the ~200 loops modeled was a result not produced (red bar) that survived the search and filtering steps.
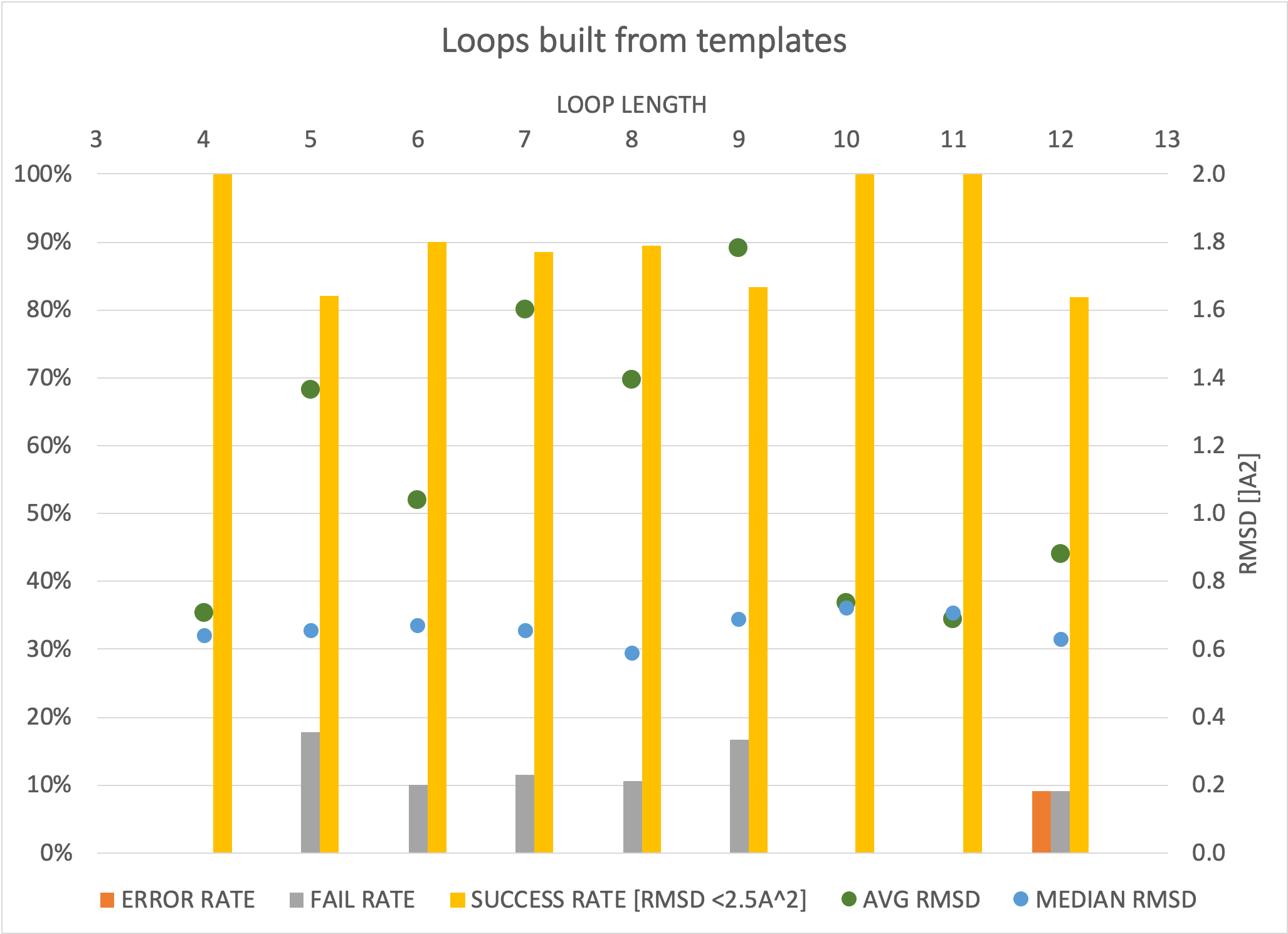
Performance assessment building loops ranging from 4-12 residues in length. Errors are when no loop was produced, failures when the backbone RMSD is larger than 2.5A from the original structure.
For the full list of new preliminary APIs, see Spruce TK 1.1.0 Release Notes.
OEChemTK: Data record preliminary API
A preliminary API for OERecord and its associated classes has been added to OEChem TK. OERecord is a data container for storing and transmitting strongly typed data and its associated metadata. A pure Python implementation of OERecord has been in use by ORION and Floe; the new C++ implementation improves performance and memory management, and makes data records available to OpenEye toolkit code. The API is only available in C++ and Python at this time.
General Notices
Support for macOS Catalina 10.15 has been added. MacOS 10.12 is no longer supported.
RHEL8 is supported across all toolkits except for the C++ CUDA-enabled toolkits and features. FastROCS TK, GPU-Omega TK, and GraphSim TK’s CUDA fast fingerprints are not supported.
C++ CUDA-enabled toolkits and features are not available on Ubuntu18. FastROCS TK, GPU-Omega TK, and GraphSim TK’s CUDA fast fingerprints are not supported.
C++ toolkits are now available for GCC 8.x.
Support for Python 3.8 has been added for all supported platforms. Python 3.6 is no longer supported for Windows toolkits.
Java toolkits are now available for macOS.
Visual Studio 2019 toolkits are now available for C++ and C#.
This is the last release to support Ubuntu16.04. Support for Ubuntu20.04 will be added in the next release.
Memory management in the Java toolkits no longer relies on the JVM to clean up objects. The new memory management significantly improves the Java toolkits performance, however requires users to manage memory. See Best Practices for Java for current best practices.