Scaling Groups
The Scaling Groups tab details the various computational scaling groups available in Orion.
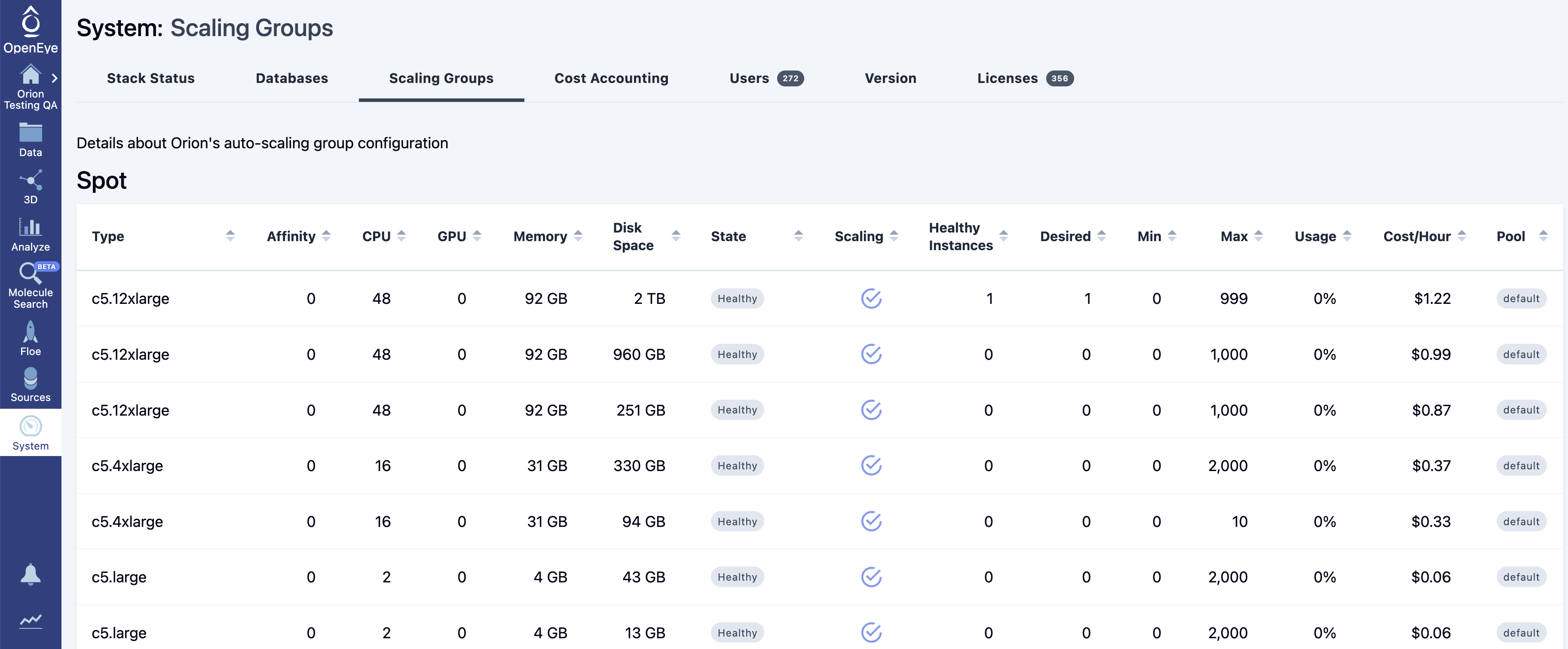
Figure 1. The Scaling Groups tab of the System Information page.
The table below represents spot and nonspot/on-demand EC2 instances.
Name |
Description |
||||
|---|---|---|---|---|---|
Type |
EC2 instance type and specification.
|
||||
Affinity |
A scheduler feature to increase the preference of a group (the default is 0). |
||||
CPU |
CPUs available. |
||||
GPU |
GPUs available. |
||||
Memory |
Memory available. |
||||
Disk Space |
Disk space available. |
||||
State |
Indicates the state of an ASG.
|
||||
Scaling |
ASG policy.
|
||||
Details |
Shows the state of the ASG and whether it is Active or Deactivated.
|
||||
Usage |
Percentage of resources currently provided by the ASG. |
||||
Cost/Hour |
Hourly instance cost. If spot, it will update regularly. |
||||
Pool |
Scheduler feature used to segregate tasks into separate scaling groups. |
||||
Edit |
Allows an Orion Stack admin to manage an ASG. Available options are Min Size, Max Size, Min Reserve,
Affinity, and State. Min Reserve, if set, ensures that there are always N idle instances for that scaling group.
|

As tasks are submitted to Orion, the scheduler decides where to place the work based on the hardware and spot requirements of the cubes, as well as other factors (such as pool or affinity). As the workload grows, more instances are launched. This is first seen as an increase in desired instances count; soon thereafter, the healthy instances should match this. Desired and healthy instances are not allowed to exceed the maximum size.
Once work is complete and Orion starts to scale down, users see the desired count drop far more quickly than the healthy count. This is for two reasons: (1) those instances are likely still working on their current task, and (2) Orion does not terminate instances immediately after they complete work as startup takes time (several minutes depending on instance type and pricing model), so they remain as hot instances for new work.
If the desired count is higher than the healthy count for a long period, there is probably limited spot availability or no availability.