Tutorial 3: NGS and Sanger Pipeline with Automated Top Lead Selection (PacBio), In-Vitro Library
Background
See Background from Tutorial 1
This is one of the most comprehensive Floes available. The goal of this tutorial is to utilize the automated selection pipeline for lead selection using both NGS and Sanger datasets simultaneously. We will use the analyze tool to identify the overlap population (see description under overlap_population :) which includes the Sanger populations.
STEP 1 - Login to Orion, Set-Up Directory, Locate Tutorial Files
Find these two additional SANGER input files:
D) Organization Data / OpenEye Data / Tutorial Data / AbXtract / SANGER_aa.xlsxE) Organization Data / OpenEye Data / Tutorial Data / AbXtract / scaffold_ref_db_aa.txtCreate a general tutorial directory and tutorial 3 subdirectory under PROJECT DIRECTORY / TUTORIALS / TUTORIAL_3 (This is your BASE DIRECTORY and should be used for all outputs for this Tutorial 3 below).
STEP 2 - Select the ‘NGS and Sanger Pipeline with Automated Top Lead Selection’ Floe
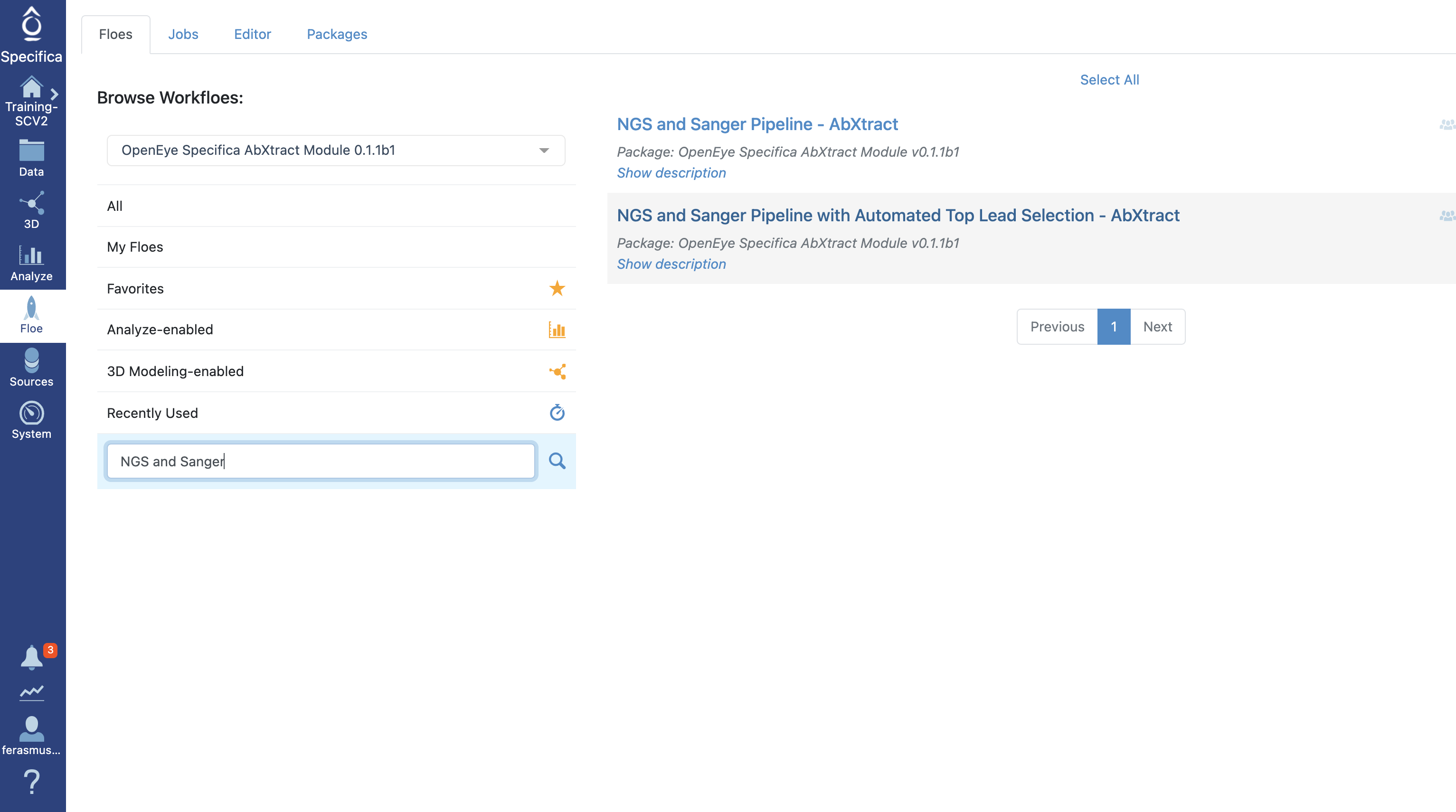
Select the tab along the left side tab titled ‘Floe’.
Click the ‘Floes’ tab.
Choose the ‘OpenEye Specifica AbXtract Module’.
Select the Floe ‘NGS and Sanger Pipeline with Automated Top Lead Selection’.
STEP 3 - Prepare Sanger Files
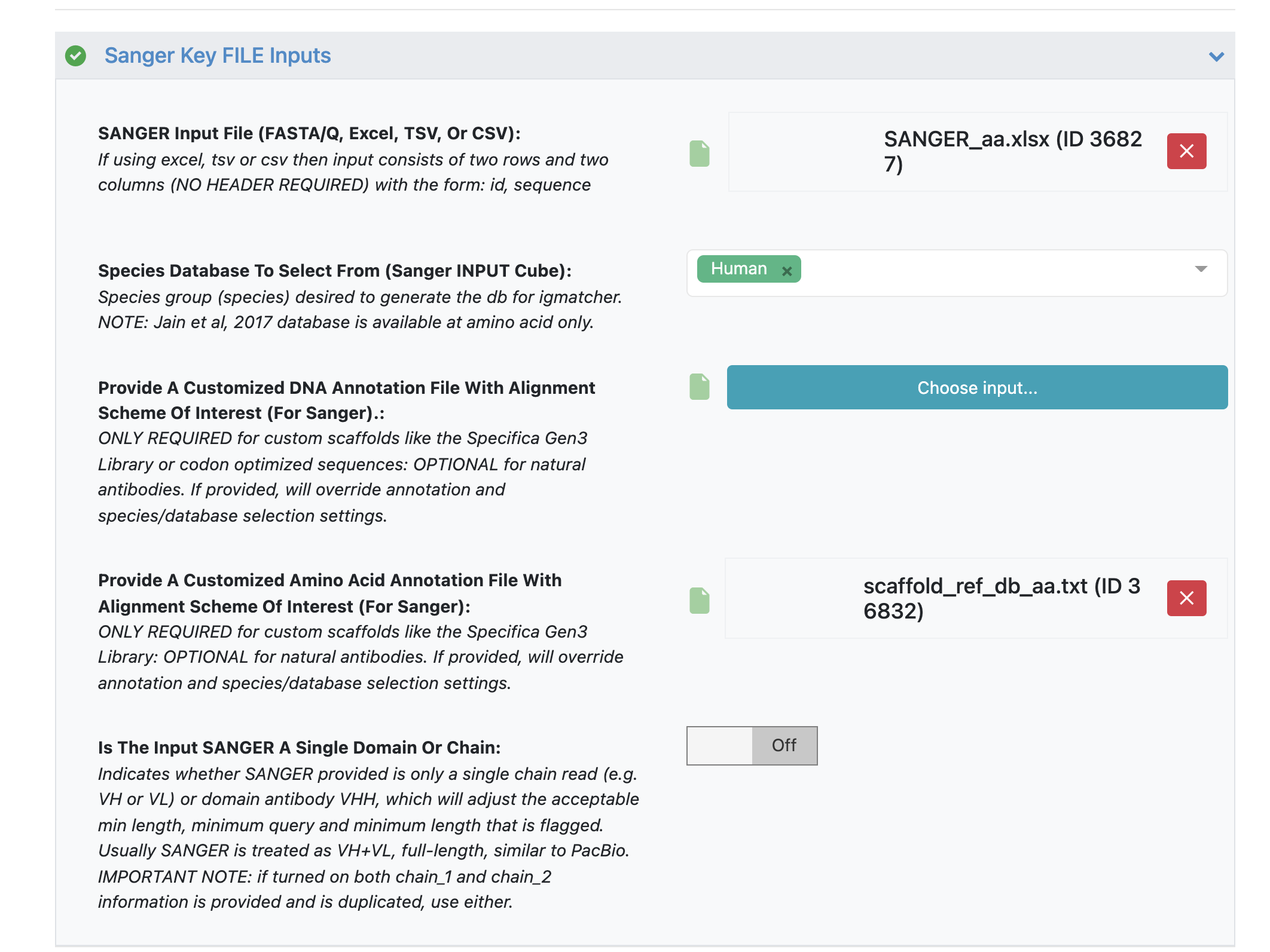
Under the ‘Sanger Key FILE Inputs’ load ‘SANGER Input File’ - ‘SANGER_aa.xlsx’.
Under parameter option ‘Provide A Customized Amino Acid Annotation File With Alignment Scheme Of Interest’ load the annotation file - ‘scaffold_ref_db_aa.txt’
Important Note
While amino acid sequences work well with the reference database using ‘human’ input, we will still load a custom annotation file to get desired scaffold name for input that matches names used in the custom DNA annotation file ‘scaffold_ref_db_codon_optimized_dna.txt’.
STEP 4 - Prepare PacBio Files and Start Job
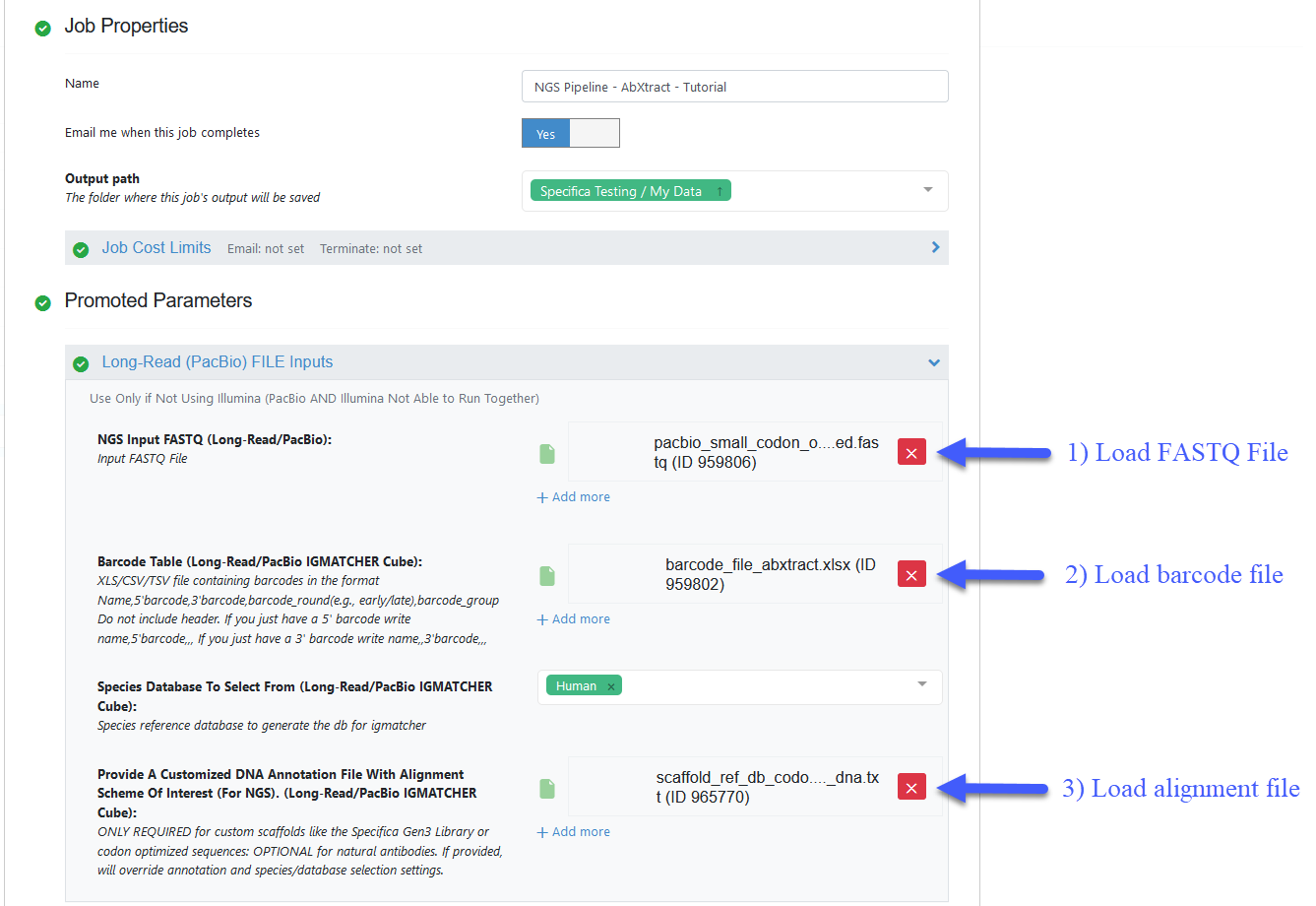
Load FASTQ file - ‘pacbio_small_codon_optimized.fastq’.
Load barcode XLSX file - ‘barcode_file_abxtract.xlsx’.
Load alignment TXT file - ‘scaffold_ref_db_codon_optimized_dna.txt’.
Important Note
All the remaining parameters can be kept as the default values. Scroll through remaining “Promoted” parameters to get a sense of these parameters.
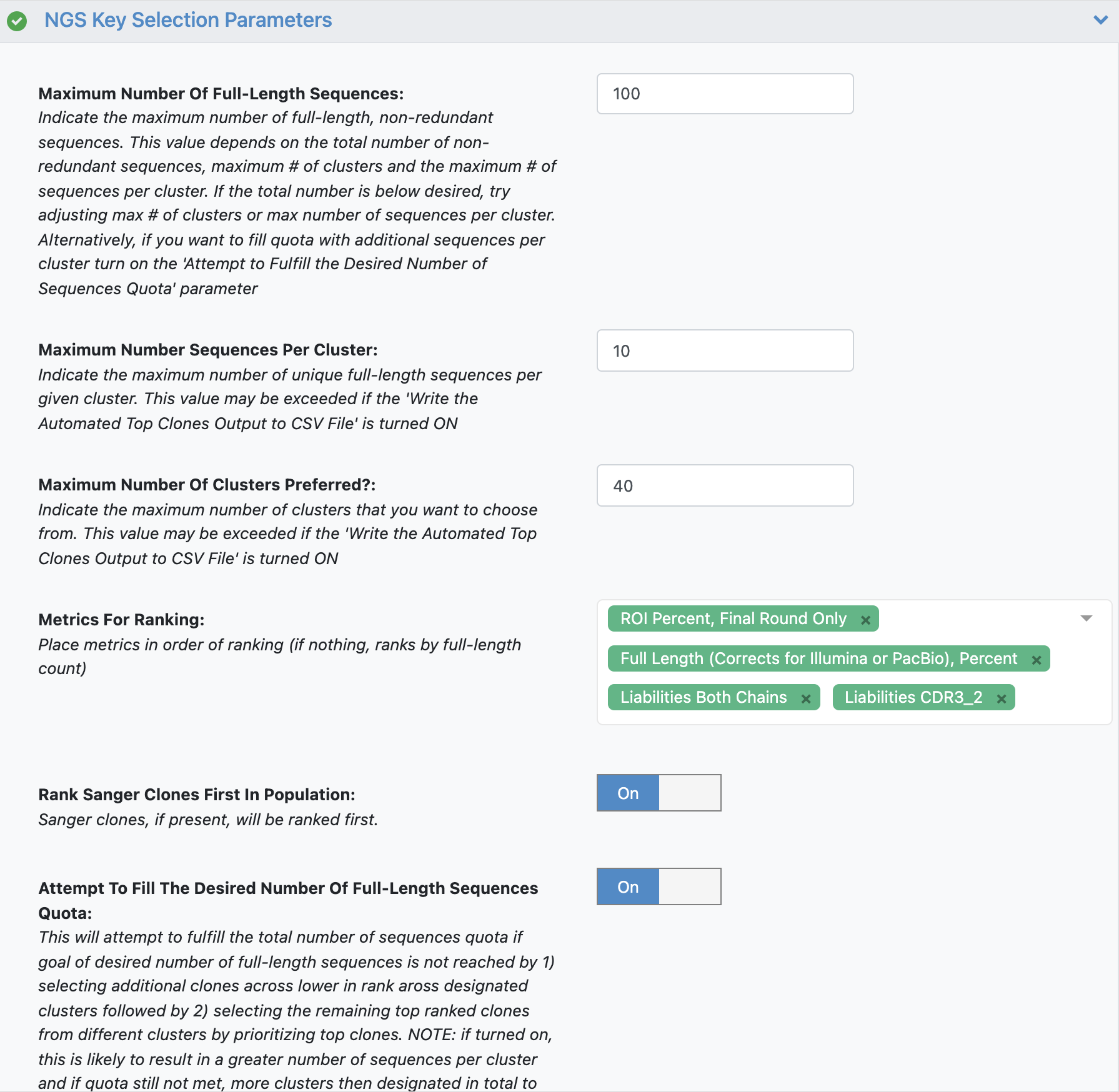
See tutorial 2 automated selection options for more details.
Important Note
The additional parameter ‘Rank Sanger Clones First In Population’ will prioritize any clones identified by Sanger input by identifying clusters associated with these Sanger clones. The automated selection will still select across clusters but will place any Sanger clones at the top of the Metrics For Ranking list.
Click ‘Start Job’.
STEP 5 - Open the Floe Report to Get a Detailed Understanding of the Selected or ‘Picked’ Population
Under the ‘Jobs’ tab find the ‘NGS and Sanger Pipeline with Automated Top Lead Select’.
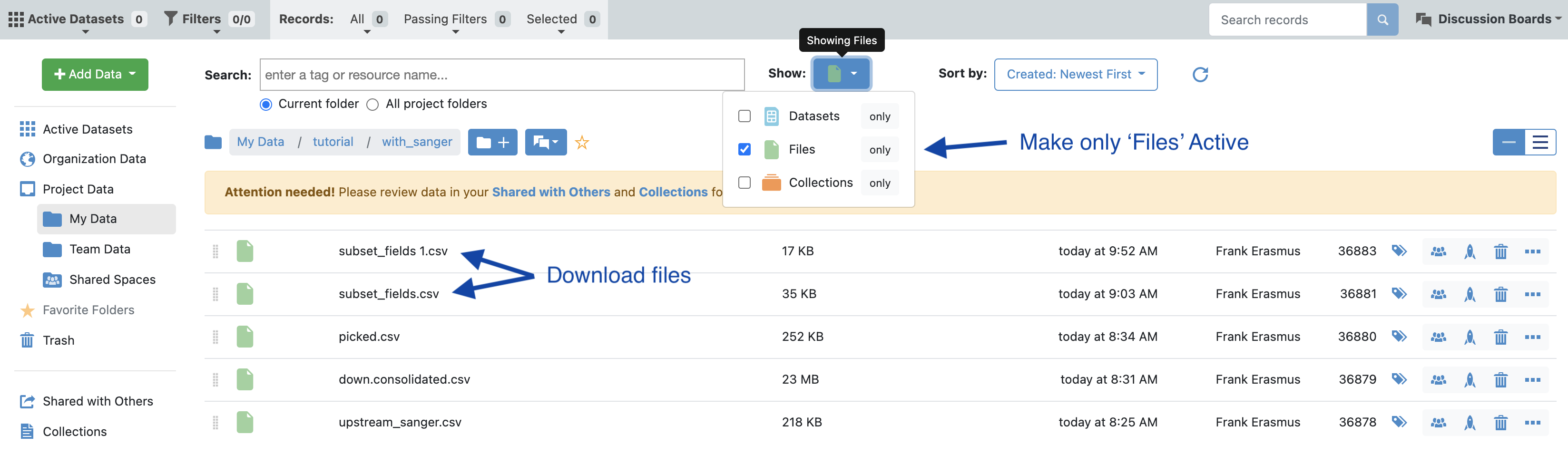
Click the ‘Show non-dataset files’ checkbox. The breakdown of datasets, collections (Floe reports) and files (CSV) are depicted here:
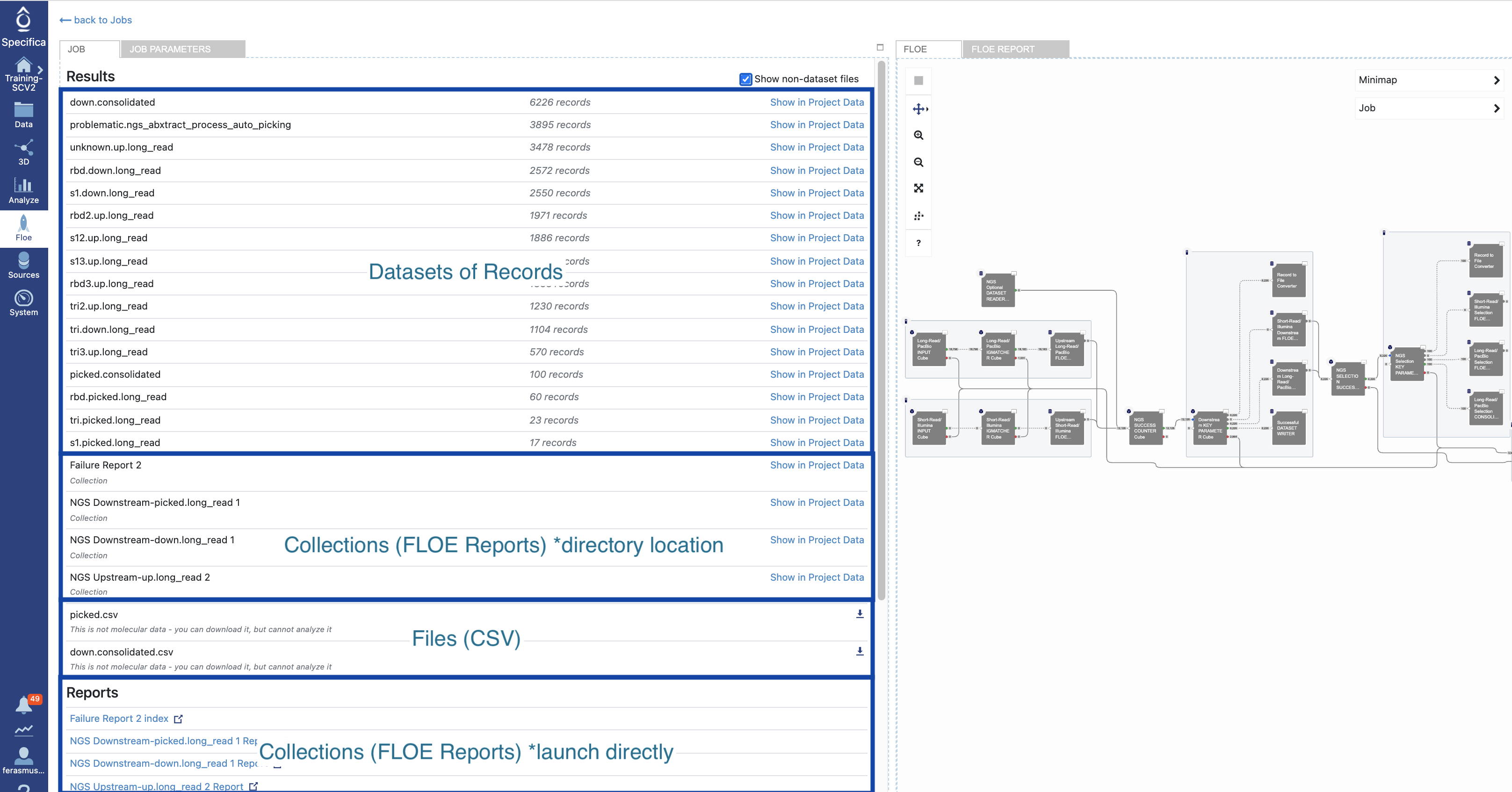
Click on the ‘NGS & Sanger Downstream-down.long_read’ under the ‘Reports’ section to launch in browser. Give it some time to load in browser.
See the ‘General stats’, which provides a snapshot of the number of non-redundant full-length, LCDR3, HCDR3, LCDR3 and HCDR3 sequences. Chain_1 represents the variable light chain (VL) and chain_2 represents the variable heavy chain (VH). The overlap shows the overlap of the region of interest (HCDR3) across the different populations.
See the ‘Cluster/Region of Interest:Sanger’, which indicates the distinct region of interest cluster id (e.g., 76F) and sequence (e.g., H3 sequence) within the Sanger population. These are the Sanger sequences clustered in context of NGS.
See the ‘Unique Sequences in NGS or Sanger Outputs Overall’, which provides an overview of the total diversity across different regions of interest that are distinct to Sanger, NGS or in both. Because this is a smaller dataset we do not get complete overlap between NGS and Sanger.
In the subpanel (e.g. Group: tri), see the table ‘Downstream NGS Clones by Cluster ID/Region of Interest within Sanger Overlap…’ we can identify the cluster id and corresponding Sanger Sequence ID. These sequence IDs are built off how the user specified the condensing of Sanger sequences (e.g., full-length) and the comma-separated id’s (e.g., 0_Sanger, 155_Sanger, 151_Sanger) indicate those Sanger clones that share the same region of interest as indicated (e.g. HCDR3). We also see the NGS metrics of the given ROI as indicated in the table.
Return to Job overview of all the datasets, floe reports and files - see similar reference
Find the the dataset titled ‘picked.consolidated’ and ‘Show in Project Data’.
Find the ‘picked.consolidated’ in the project directory. Select the Workfloe button.
Under Search Bar, search for ‘Subset the Number of Fields for Export’ and click ‘View all Workfloe options’.
Keep following fields (for more details, see key fields reference):
A) seq_idB) match_name_1C) match_name_2D) cdr3_aa_2E) sequence_aa_1F) sequence_aa_2G) clusterH) well_id (under Sanger Overlap Fields to Keep)Click ‘Start Job’.
Next go back to the data directory and activate the ‘picked.consolidated’ and the ‘down.consolidated’ dataset together.
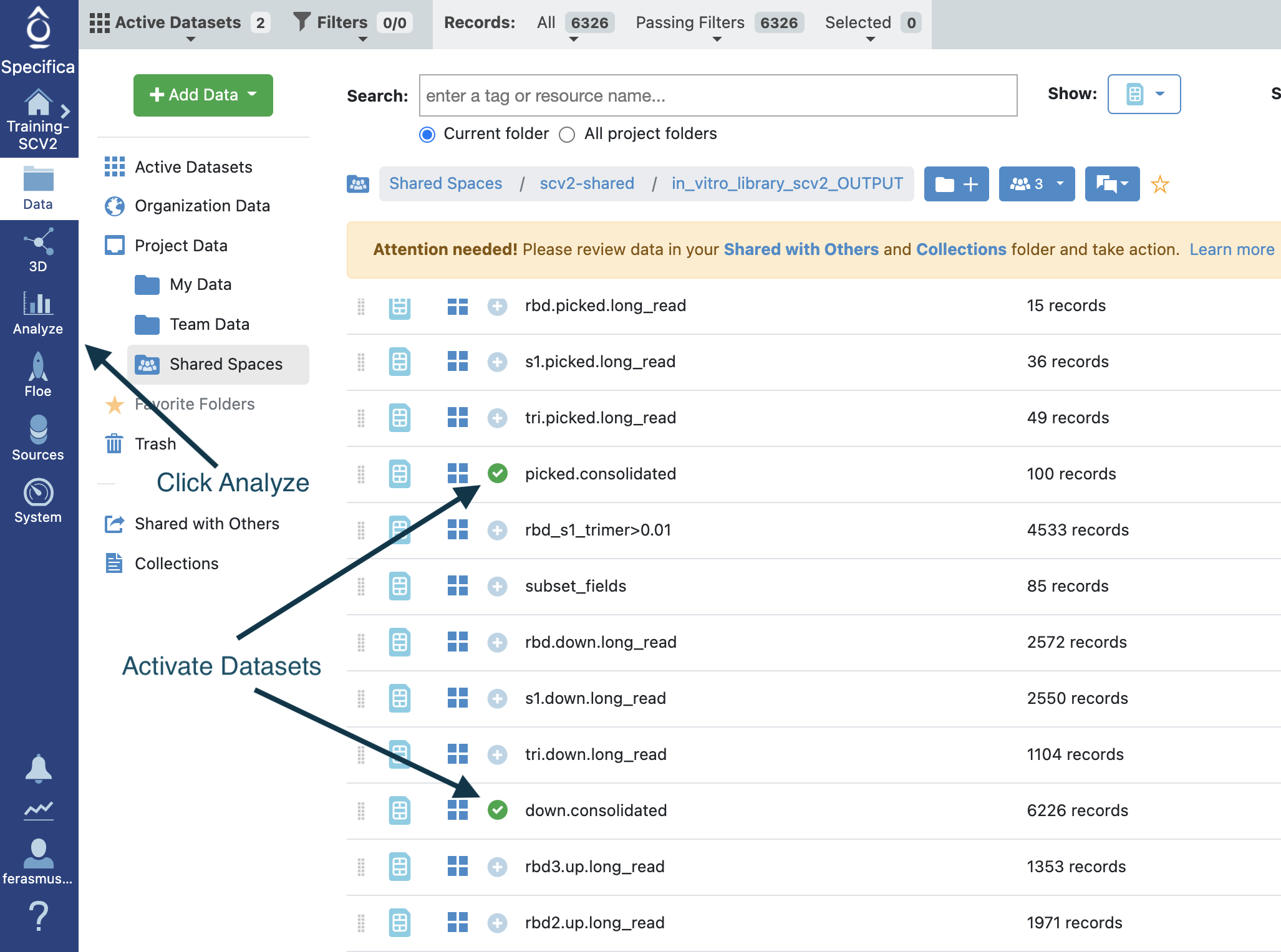
Open in the Analyze tool.
STEP 6 - Subset NGS Only Population by Cluster and Overlap_Population
Click the Analyze tab to activate the interactive tool.
select y-axis - percent_roi_final.
Click the ‘Data Handling’ tab near top:
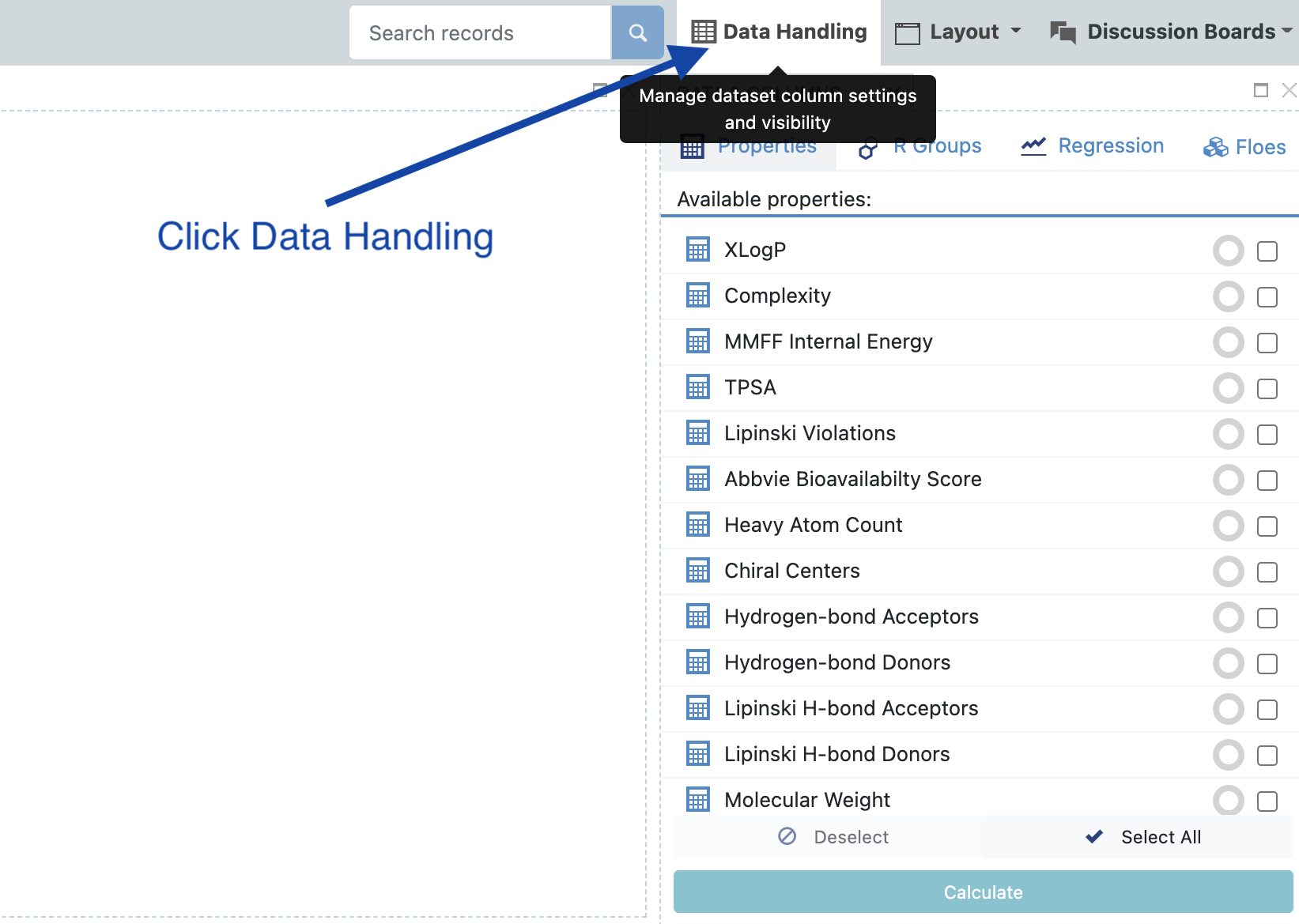
Make sure that under ‘Display’ ‘log2_enrichment_roi’ has all options selected (or at least in spreadsheet and plot) and click ‘Apply’.
Select x-axis - log2_enrichment_roi.
Important Note
If option not available select ‘count’ to initialize then select the y-axis after data has loaded.
Change the color of the records by selecting the plot settings and choosing ‘Dataset Name’.
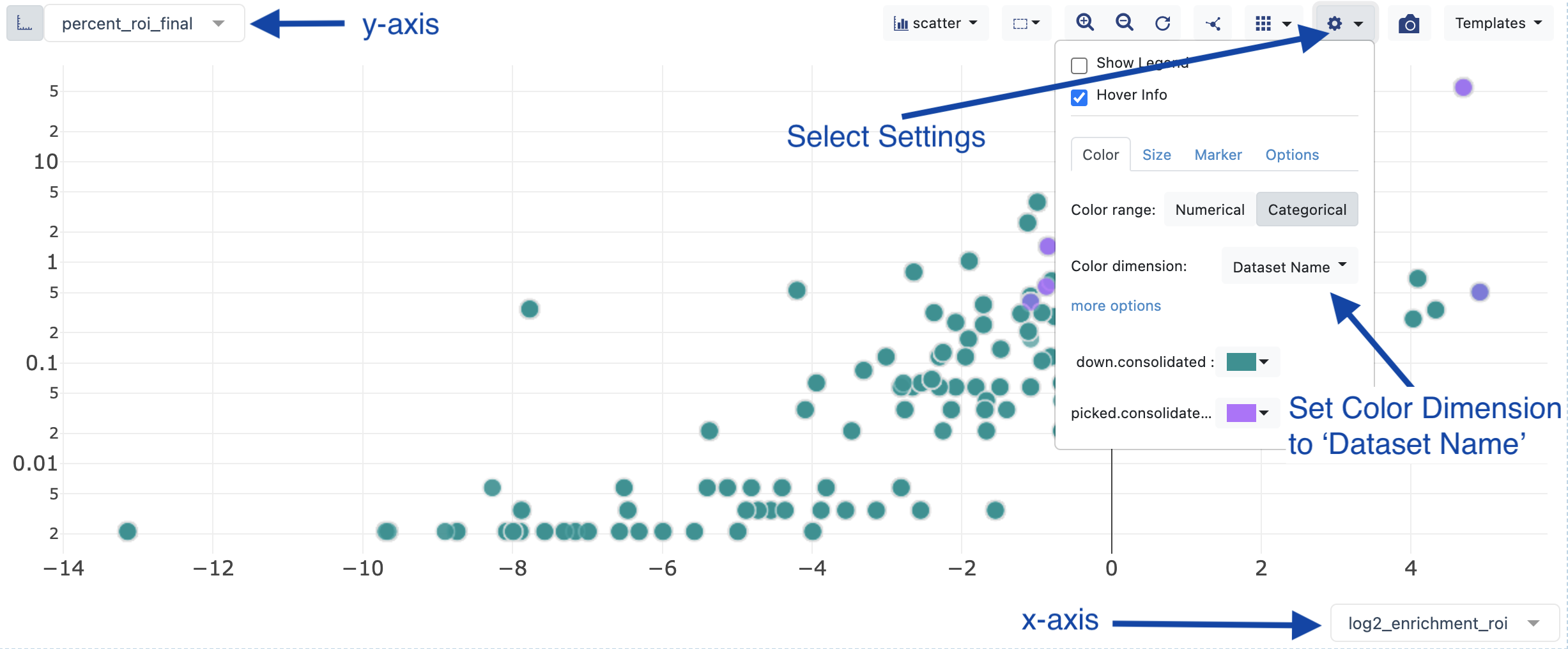
Use the Shift key on the keyboard to select any remaining Non-Picked Populations that are highly enriched in population. Toggle between lasso and rectangle select.
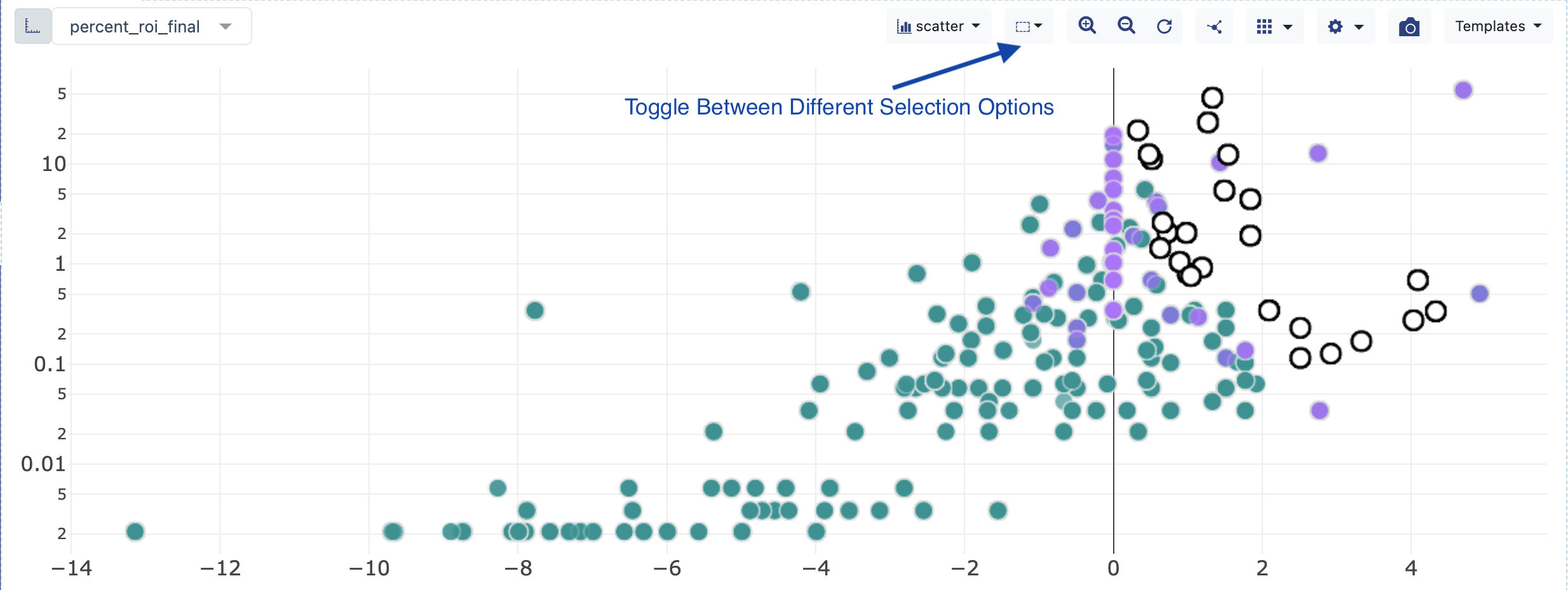
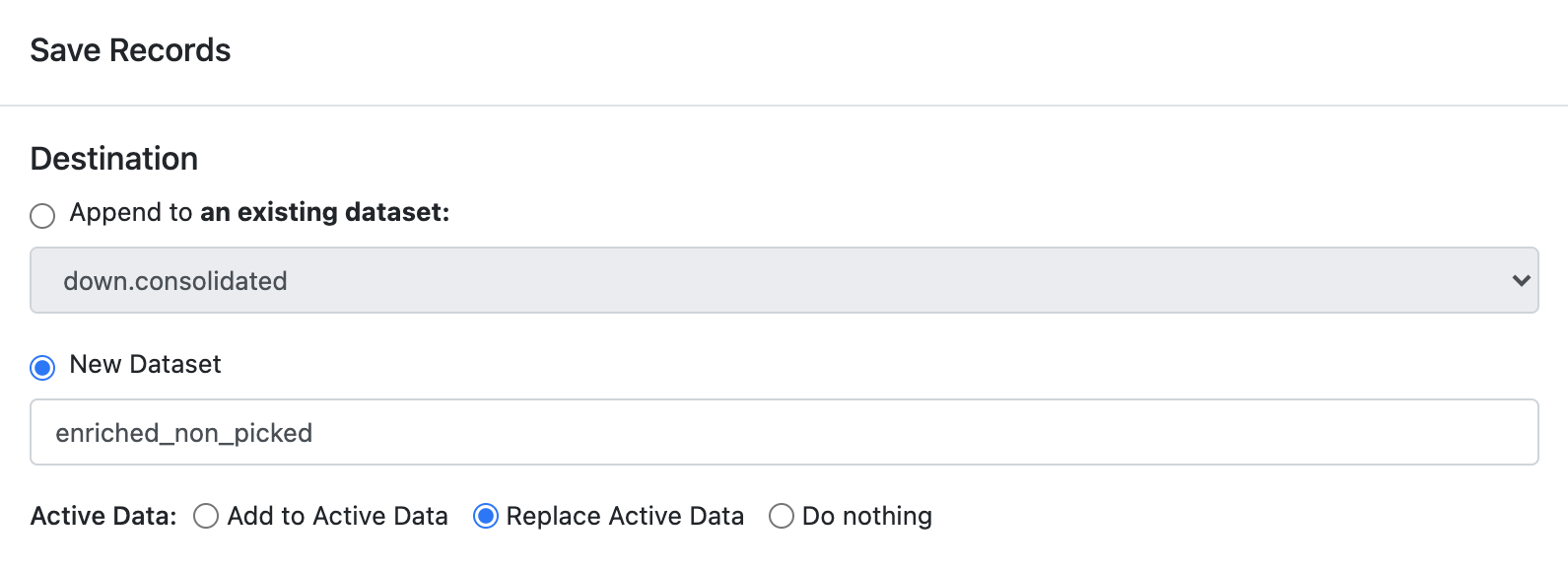
With the selected population click the ‘Selected’ option near the top > click ‘Save Records’ > ‘New Dataset’ > provide a name ‘enriched_non_picked’ and > ‘Replace Active Data’.
Allow the new dataset loads into the interactive interface. If it does not load properly, remove all active datasets, find ‘enriched_non_picked’ dataset in project directory, make active, and reload in Analyze.
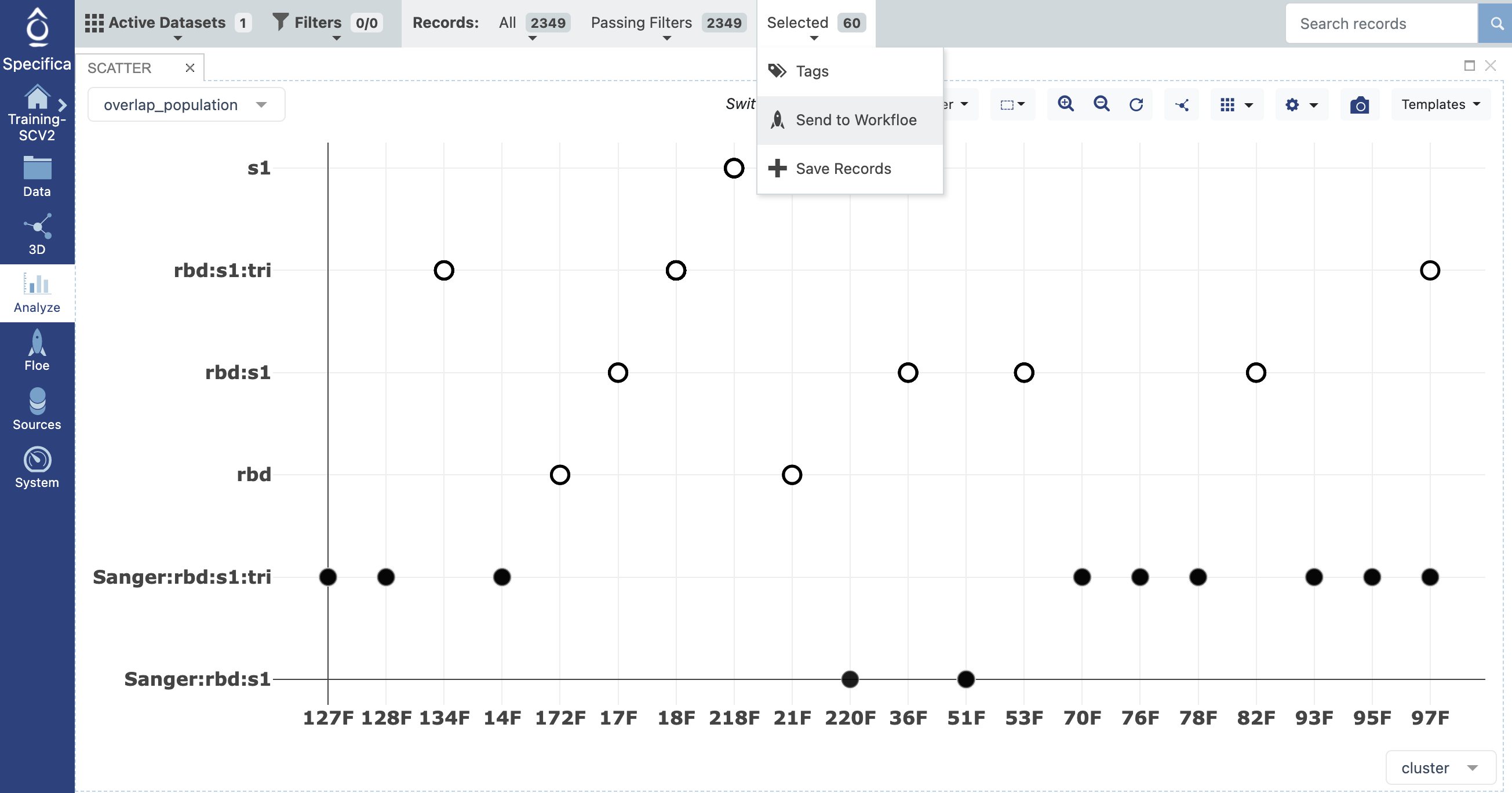
set x-axis - cluster.
set y-axis - overlap_population.
Select only populations with regions of interest not identified in Sanger. Send selected records to Workfloe.
In data directory make only files active and download the csv files corresponding to the selected population.