Datasets
Two sets of input datasets are utilized in this tutorial.
The first one is a ligand dataset obtained from the supplemental materials in a paper from Sutherland and coworkers [Sutherland-2004],
which contains 66 inhibitors of glycogen phosphorylase b (GPB)
with 3D conformers and charges provided. This is the GPB benchmark dataset.
(GPB.oedb)
Among the 66 ligands, 44 of them are utilized for model training and the rest are for external model validation.
The external validation ligands have a value of 1 for the External Validation Set Tag Value field.
The Unit for Potency parameter contains experimental binding affinity data in log units.
The second datasets are curated and used to build models for β‐secretase 1 (BACE-1) inhibitors.
A set of 20 receptors (BACE1_recs_20.oedb) is
provided for Posit pose conformer generation. This is the BACE-1 receptor dataset.
The input ligand dataset (BACE1_2D_400.oedb) contains 400 ligands
without 3D conformers or charges. This is the BACE-1 ligand dataset.
The Unit for Potency parameter contains experimental binding affinity data in log units.
Note
If you want to do external validation within the model builder floe, the external validation ligands need to be manually tagged. The alternative is to run the model builder floe followed by the model validation floe.
3D QSAR Model: Builder Floe
The 3D QSAR Model: Builder Floe builds a baseline 2D-GPR model and four individual 3D models: ROCS-kPLS, ROCS-GPR, EON-kPLS, and EON-GPR by default, and bases the final prediction on the consensus of the individual model predictions. The prediction from the consensus model is provided as the weighted average of all five individual models with their corresponding prediction confidence as weights; the prediction confidence is obtained as the median of the individual model confidences.
The required input of the floe is a ligand dataset with potency values. A second input, containing receptors or reference molecules, is required if you want to generate conformers using Posit or FlexiROCS. Below are two examples for running the floe with either provided or generated conformers.
Running the Floe with Provided Pre-aligned Conformers
Tip
The floe in this example typically takes around 10 minutes to finish and costs less than $0.5.
For this example, the benchmark dataset is utilized as the input ligand dataset. The steps to run the 3D QSAR Model: Builder Floe are detailed below.
Select the 3D QSAR Model: Builder Floe in Orion and a Job Form will pop up.
Change the job name, output path, and name of output datasets, if desired.
For the Ligand Database, choose the GPB benchmark dataset.
Under the Model Parameters section, select the set of 3D models to build and whether to include 2D-GPR model in the COMBO model prediction.
For this tutorial, we leave all fields at their default values.
Under the 3D Conformer Parameters section, select whether to use the 3D input structures. Minimum Posit Probability only applies to input dataset generated using Posit, and will be ignored in this example.
For this tutorial, we leave all fields at their default values. With Use Input 3D turned On, molecules with provided input 3D structures will be utilized as is.
Under the Charge Method Parameters, select whether to use input charge, and if not the desired charge method. For this tutorial, we turn On Use Input Charges.
Note
If a molecule can’t be assigned charges, or does not contain charges when the current_charges option is selected, the molecule will not enter the model building process.
Under Potency Parameters, specify the name of the potency field, the minimum and maximum potency for a record to be considered valid, and the unit for potency. If the input binding affinity data has the units micromolar or nanomolar or kcal/mol or kJ/mol, it will be converted to log units for model building. A temperature of 300 K is used for conversion. Here, we leave all fields to their default values.
Note
If an input molecule is considered to be invalid due to its potency being out of range, the molecule will not enter the model building process.
Under the Cross Validation Parameters, select the desired splitting method for cross-validation experiments. The default splitting method is random. Here we switch to leave one out since we have a small dataset.
Under the External Validation Parameters, select whether to do external validation.
For this tutorial, we turn Do External Validation On and leave all other fields to their default values.
Note
Molecules identified as belonging to the external validation set won’t go into the model building process. If Do External Validation is turned On, but the external validation set comes out to be empty, the floe will throw an error.
Click the “Start Job” button to launch the floe.
Floe Output Datasets
The 3D QSAR Model: Builder Floe outputs three datasets, with the external validation dataset and training set conformer dataset being optional.
Output Model Dataset (default name = Output for 3D QSAR Model: Builder): Contains the model and stores the receptors/reference molecules, if provided.
External Validation Output Dataset (default name = External Validation Output): Contains the individual and COMBO model predictions, along with the corresponding prediction confidence for the external validation set.
Training Conformer Output Dataset (default name = Training Conformer Output): Contains the conformers used for model building.
The model datasets built from this floe can be used as input for other floes in this package, which focus on prediction, external validation, and interpretation, as mentioned later in this tutorial.
Note
The model dataset is only meant to be used as input for other floes. For model performance, refer to the Floe Reports.
Floe Reports
The 3D QSAR Model: Builder Floe generates multiple reports.
Training Set Statistics
This section contains information regarding the training set used in model building:
Statistics and histograms of input potency. Figure 1 shows the corresponding plot obtained using the GPB dataset.
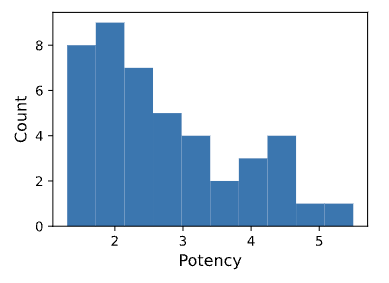
Figure 1. Input potency histogram from Training Set Statistics report.
Statistics and histograms of pairwise similarities based on the relevant descriptors for various 3D-QSAR models and 2D baseline model. Figure 2 shows the corresponding plots obtained using the GPB dataset.
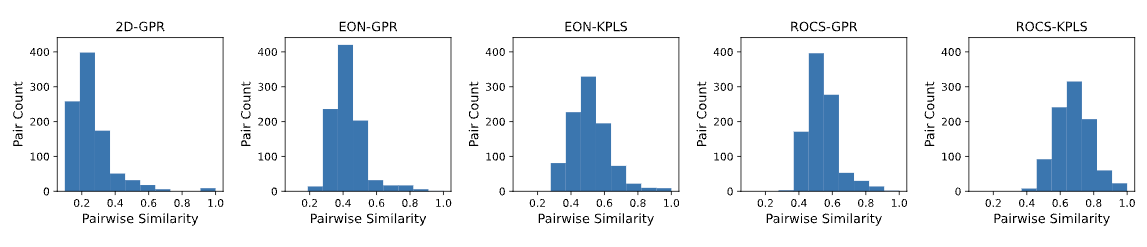
Figure 2. Pairwise similarity histograms from Training Set Statistics report.
Plots of | Delta Potency | versus Pairwise Similarity for different models show whether molecules similar in descriptor space are also similar in potency. Irregularities in such plots indicate potential activity cliffs in the training dataset. Figure 3 shows the corresponding plots obtained using the GPB dataset.

Figure 3. | Delta Potency | vs. Pairwise Similarity from Training Set Statistics report.
Note
All pairwise similarities are normalized using the corresponding upper bound.
Feature Optimization - ROCS-kPLS
The optimal number of features, or the hyperparameter for a kPLS model, is obtained based on cross-validation statistics. Pearson’s correlation coefficient squared (\({r^2}\)) from cross-validation is plotted against the corresponding number of features, and the optimal is selected by picking the value corresponding to the maximum of \({r^2}\). Figure 4 shows the result obtained for the ROCS-kPLS model. In this case, the optimal number of features is determined to be 10.
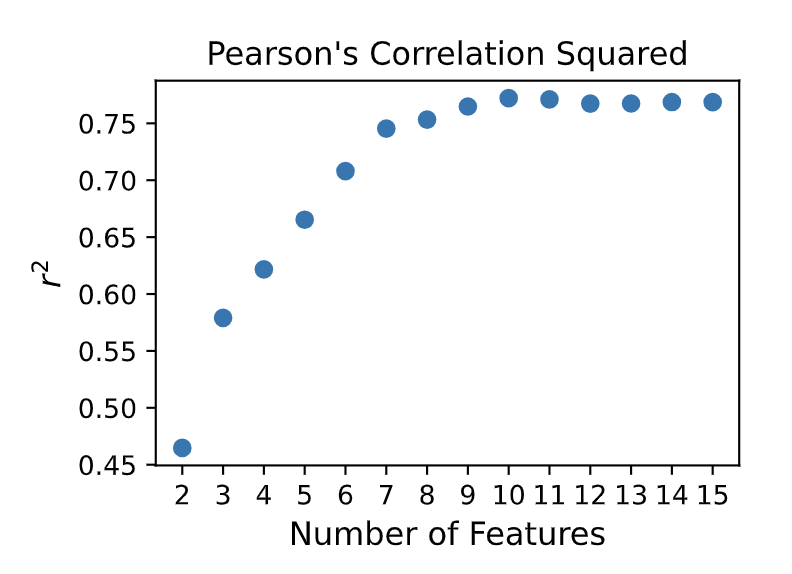
Figure 4. ROCS-kPLS hyperparameter optimization results from Feature Optimization - ROCS-kPLS report.
Feature Optimization - EON-kPLS
The feature optimization details for the EON-kPLS model are similar to those for the ROCS-kPLS model.
Cross Validation Statistics
These are statistics and histograms obtained from combined validation sets from all cross-validation splits.
Validation statistics include:
Pearson’s correlation coefficient squared (\({r^2}\))
Kendall’s tau
Coefficient of Determination (COD)
Median absolute error (MAE)
Relative median absolute error (RMAE)
Note
Unlike \({r^2}\), COD can be negative. A baseline model which always predicts the average of training set, gives a COD of 0. Models that have worse predictions than this baseline will have a negative COD.
Predicted Potency versus Actual Potency, colored by confidence level and along with parity and error lines (+/- 1 log unit), are plotted for all individual models for visualization purposes. Plots of Fraction Accurate versus Confidence Level are provided to see how the actual accuracy correlates with estimated accuracy. For individual 3D and 2D models, plots of Fraction Accurate versus Minimum Dissimilarity to Training Set are also provided. Figure 5 shows the cross-validation results for COMBO model using the GPB dataset.
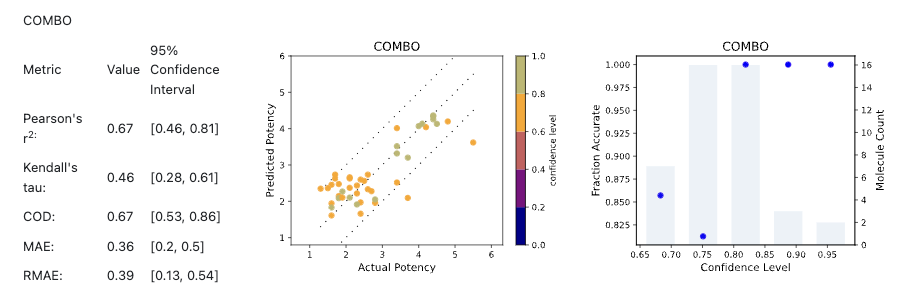
Figure 5. Results for COMBO model from Cross Validation Statistics report.
External Validation Statistics
Since the input dataset contains an external validation set, the 3D QSAR Model: Builder Floe also produces an external validation report in a similar format as the cross-validation report.
Running the Floe Using Posit as Conformer Generation and Alignment Method
Tip
The floe in this example typically takes around 50 minutes to finish and costs around $2.
For this example, the receptors and the ligand dataset are used as input datasets. The steps to run the 3D QSAR Model: Builder Floe are detailed below.
Select the 3D QSAR Model: Builder Floe in Orion and a Job Form will pop up.
Change the job name, output path, and name of output datasets, if desired.
For the Ligand Database, choose the BACE-1 ligand dataset, and for Receptors/Reference Molecules, select the BACE-1 receptor dataset.
Leave all Model Parameters at their default values.
Under the 3D Conformers Parameters, turn Off Use Input 3D and turn On Output Training Conformers. Leave Minimum Posit Probability at its default value of 0.5. Pose conformers will be generated by Posit by default.
Note
If a dataset of reference molecules is provided instead, conformers will be generated by FlexiROCS. If both receptors and reference molecules are provided, the reference molecules will be ignored.
Note
If the Posit pose conformer for a molecule has a confidence, or Posit probability below 0.5, the conformer is considered to be invalid and will not enter the model building process. The same applies for FlexiROCS conformers.
Leave all Charge Method Parameters at their default values. The default option for the Charge Type parameter is am1bcc.
Leave all Potency Parameters at their default values.
Leave all Cross Validation Parameters at their default values.
Leave all External Validation Parameters at their default values.
Click the “Start Job” button to launch the floe.
Floe Outputs
Using the BACE-1 input datasets, the 3D QSAR Model: Builder Floe generates an output model dataset with 25 records (5 model records and 20 receptor records). An optional output dataset Training Conformer Output is also generated, containing the aligned pose conformers of 289 training ligands, with the remaining 111 training ligands reported in the failure report due to a Posit probability below 0.5.
Note
In this example, the 2D-GPR model is built using all 400 molecules, while the 3D models are only built with 289 molecules. The size of the training set is also shown in Training Set Statistics report.
Figure 6 shows the cross-validation results for COMBO model using the BACE-1 dataset.
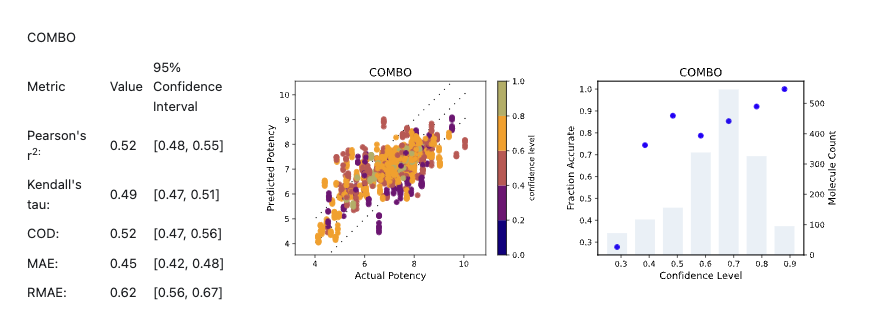
Figure 6. Results for COMBO model from Cross Validation Statistics report using the BACE-1 dataset.
3D QSAR Model: Predictor Floe
The 3D QSAR Model: Predictor Floe takes two input datasets, one being the ligand dataset for making predictions, and the other is the model dataset generated from the 3D QSAR Model: Builder Floe. Similar to the model builder floe, you can select whether to use input 3D structures for the test dataset or not. For molecules without input 3D structures, poses will be generated either from Posit or FlexiROCS, based on whether receptors or reference molecules are present in the model dataset. The output from this floe is a single dataset that contains the predicted potency and prediction confidence from different individual models, as well as the consensus model.
3D QSAR Model: Validation Floe
The inputs to the 3D QSAR Model: Validation Floe are similar to those of the 3D QSAR Model: Predictor Floe, that is, a ligand dataset and a model dataset. However, unlike the predictor floe, the validation floe expects the input ligand dataset to contain an additional field containing actual potency values. These actual potency values are used against the predictions to perform validation and corresponding statistics. In addition to an output validation dataset that contains predictions on the input ligand dataset, this floe also generates a validation report similar to the external validation report generated from the 3D QSAR Model: Builder Floe.
3D QSAR Model: Interpretation Floe
The 3D QSAR Model: Interpretation Floe can be used to obtain interpretation information based on the kPLS models. By default only interpretation of the ROCS-kPLS model is performed. EON-kPLS model interpretation can be turned on by adding it to selected models.
This floe takes a model dataset generated from the 3D QSAR Model: Builder Floe as an input.
The output dataset Output for 3D QSAR Model: Interpretation contains different types of grids and high and low surfaces corresponding to various probes used. Table 1 lists the different types of surfaces and their corresponding atom probes. Color atoms of type Acceptor, Donor, Hydrophobe, Rings, Cation, and Anion are defined based on Implicit Mills Dean color force field and used for ROCS-kPLS model interpretation, while probes of type Positive and Negative are used to interpret EON-kPLS model.
Surface Name |
Probe Atom Type |
|---|---|
Volume |
Carbon atom |
Acceptor |
Color atom of type Acceptor |
Donor |
Color atom of type Donor |
Hydrophobe |
Color atom of type Hydrophobe |
Rings |
Color atom of type Rings |
Cation |
Color atom of type Cation |
Anion |
Color atom of type Anion |
Positive |
Sodium atom of +1 charge |
Negative |
Chloride atom of -1 charge |
Tip
The floe in this example typically takes around 15 minutes to finish and costs less than $0.5.
Here we use the GPB output model dataset from the previous 3D QSAR Model: Builder Floe as input to run the 3D QSAR Model: Interpretation Floe. The floe generates two datasets that can both be visualized in Orion 3D. The output dataset Output for 3D QSAR Model: Interpretation provides 3D visualization of kPLS model interpretation. Figure 7 shows an image of the high surfaces for hydrogen bond donor and rings.
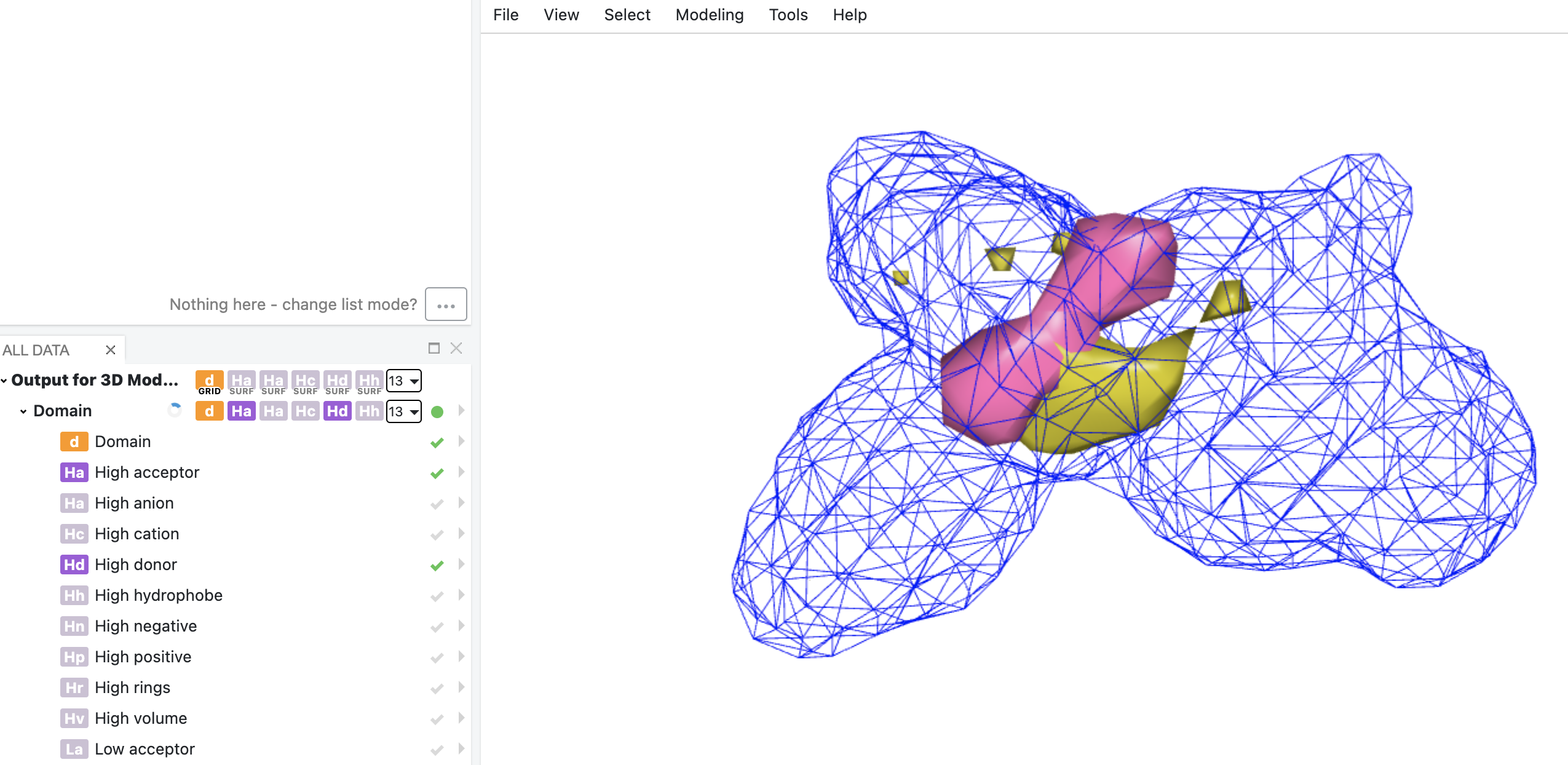
Figure 7. High hydrogen bond donor (blue) and rings (yellow) surfaces from kPLS interpretation. Top two potent molecules in the training set were shown for context.
The other output dataset ROCS Query Output contains a ROCS query that can be used for virtual screening purpose, with a grid representation for the shape part and a set of color atoms. 3D scalar grids can be visualized with isosurfaces (surfaces representing points of a constant value) corresponding to different contour values. Orion by default only visualizes the shape grid of the query with one contour value. To explore the shape grid using different contour values, the shape grid itself is written out separately in the output dataset as well. Figure 8 shows an image of the visualized ROCS query.
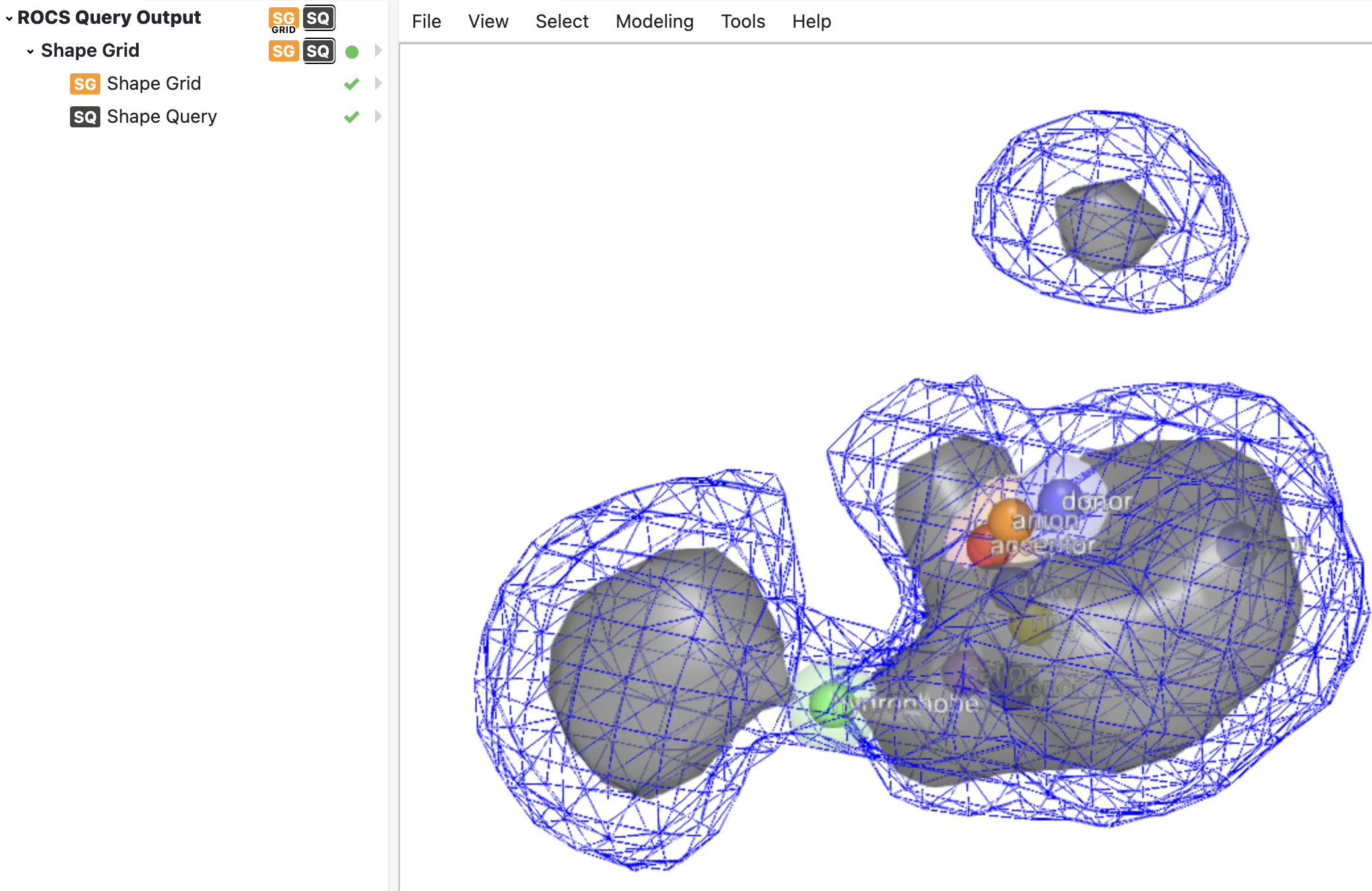
Figure 8. ROCS query visualized in Orion with gray surface and color atoms. The shape grid is also visualized separately with blue surface using a chosen contour value of 0.1.
Note
Due to the discrepancy between predicted potency score space and molecular shape space, the scale of the shape grid values can be very different from a normal molecule query, leading to smaller Tanimoto values for ROCS virtual screening results. In this case, absolute Tanimoto values are not as meaningful.