Input Name Representation
The oeiupac library currently processes NULL (zero) terminated ASCII character strings; therefore Greek characters, symbols, fonts and superscripts must be transliterated into the printable subset of ASCII. When parsing compound names, the oeiupac library considers both spaces and tab characters as interchangeable, and any number of consecutive ‘whitespace’ characters are treated as a single space.
Currently, the name parsing is case insensitive, allowing arbitrary mixing of upper and lower case characters, e.g. initial letter capitalization.
Greek characters are understood in a number of different representations.
Character |
Friendly Code |
Decimal Code |
Hex Code |
Unicode |
Addl1 |
Addl2 |
Addl3 |
Addl4 |
|---|---|---|---|---|---|---|---|---|
\(\alpha\) |
α |
α |
α |
\U03B1 |
.alpha. |
$a |
${a} |
alpha |
\(\beta\) |
β |
β |
β |
\U03B2 |
.beta. |
$b |
${b} |
beta |
\(\gamma\) |
γ |
γ |
γ |
\U03B3 |
.gamma. |
$g |
${g} |
gamma |
\(\delta\) |
δ |
δ |
δ |
\U03B4 |
.delta. |
$d |
${d} |
delta |
\(\epsilon\) |
ε |
ε |
ε |
\U03B5 |
.epsilon. |
epsilon |
||
\(\lambda\) |
λ |
λ |
λ |
\U03BB |
.lambda. |
$l |
${l} |
lambda |
+/- |
&PLUSMN |
± |
± |
\U00B1 |
Note: Addl[1-4] are additional identifiers.
For example, the strings ‘$a’, ‘${a}’, ‘alpha’, ‘.alpha.’, ‘α’, ‘α’ and ‘α’ are all understood to represent the Greek character alpha, (\(\alpha\)).
Output Name Representation
Unrecognized functional groups, linkers or ring systems are denoted in the generated name as the string ‘BLAH’. As much of the name as possible is generated resulting in compound names such as ‘dichloroBLAHcarboxylic acid’. Generated compound names are entirely lower case, with no initial capitalization. Upper case characters are generated for locants and, as described above, for BLAH.
Names are generated using a set of markup tokens which can be further processed for output to the desired format.
Greek characters are indicated with the dollar character followed by a single letter. In this formalism, ‘$a’ represents the Greek character alpha, \(\alpha\), ‘$b’ the Greek character beta, \(\beta\), etc.
Superscripts are indicated by surrounding the superscripted text with caret and curly braces. Hence ‘$l^{5}’ represents the Greek character lambda followed by a superscript five, i.e. \(\lambda^5\). Similarly, ‘pentacyclo[4.2.0.0^{2,5}.0^{3,8}.0^{4,7}]octane’ would be the von Baeyer system name for cubane.
Subscripts are are indicated by surrounding the superscripted text with underscore and curly braces. Hence ‘C_{60} Fullerene’ is a generated name for Buckminsterfullerene.
Italics, used for stereochemistry and locants, are indicated with a tilde and curly braces. An example is: ‘(2~{R})-butan-2-ol’.
The markup tokens are converted into appropriate markup for a particular use during the conversion of the raw name to the desired final character set.
Translation of names to alternate languages may result in characters outside of the default ASCII character set being used. In this case, the characters are encoded as escaped unicode, eg: ‘uXXXX’. The actual output characters are generated in the final character set conversion.
Multiple components in a disconnected molecule, apart from common salts and counter ions, are separated from each other by a semicolon followed by a space. Mixtures containing salts are written ordering the cations before the compound name, followed by anions, followed by any common neutral molecules (e.g. hydrate or hydrochloride).
Enhanced Stereochemistry
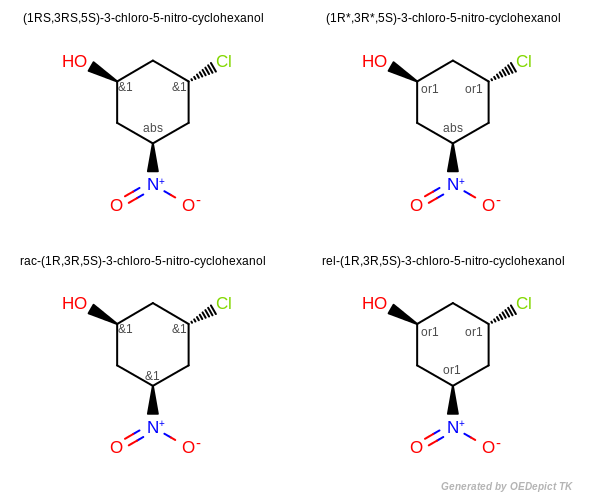
Enhanced Stereochemistry
Note
Enhanced stereochemistry is only supported in for molecules which are represented using MDL V3000 Format.
Naming recognizes enhanced stereochemical features as embodied in the V3000 file format. V3000 allows the specification of AND and OR stereochemical atom groupings. An AND grouping corresponds to a mixture of structures with the center(s) as indicated and their inverse configuration. An OR grouping corresponds to either the isomer as indicated or its inverse configuration. Absolute, unspecified, AND, and OR stereocenters can all be present in single molecule.
Figure: Enhanced Stereochemistry illustrates enhanced stereochemical names generated using the Lexichem TK. Centers in an AND grouping are designated with “RS” or “SR”. Centers in an OR grouping are designated with “R*” or “S*”.
For chemical structures with multiple chiral centers where only some are designated as AND (see top left image), the descriptors “RS” and “SR” are used to denote AND centers.
For a structure where all of the stereocenters are designated as AND, the structure represents a molecule and its enantiomer. In that case (even though the V3000 format does not explicitly define the ratio of enantiomers), the molecule is named as a racemate, with a “rac” prefix (see bottom left image).
For chemical structures with multiple chiral centers where only some are designated as OR (see top right image), the descriptors “R*” and “S*” are used to denote the OR centers.
For a structure where all of the stereocenters are designated as OR, the structure represents a molecule or its relative inverse configuration. In that case the molecule is named with a “rel” prefix. (see bottom right image).
The IUPAC standard recommends naming structures so the first AND indicator and the first OR indicator in the name are “R”, “RS”, or “R*” as appropriate. When generating a name from a structure, this is easily accomplished by inverting the stereo designation on every center in the stereo grouping. For example, the names “rac-(2R,4R)-4-aminopentan-2-ol” and “rac-(2S,4S)-4-aminopentan-2-ol” are equivalent since they both mean: “a mixture of the (2R,4R) and (2S,4S) isomers”. In this case IUPAC conventions recommend using the “rac-(2R,4R)” name.
This choice of recommended name may be a cause for confusion since the atom/bond block of the V3000 molfile indicates a particular configuration and it is possible that the generated name will not appear to correspond to the configuration as found in the atom/bond block. To mitigate the potential for confusion, only the IUPAC and Systematic style of output names perform the inversion. This allows the user to control whether or not the inversion occurs. Comparing the IUPAC and OpenEye style names will give an indication whether or not the inversion is occurring.
For more details please refer to section P-92.1.2 and P-92.1.3 of the Nomenclature of Organic Chemistry [IUPAC-2014].
Note
IUPAC nomenclature currently only allows for a single AND group and a single OR group on a molecule. The V3000 format allows for multiple independent AND and OR groups. Names are generated as if all the AND centers are in a single AND group and all the OR centers are in a single OR group. This will be remedied when IUPAC defines a naming convention for these more complex cases.
Isotopes
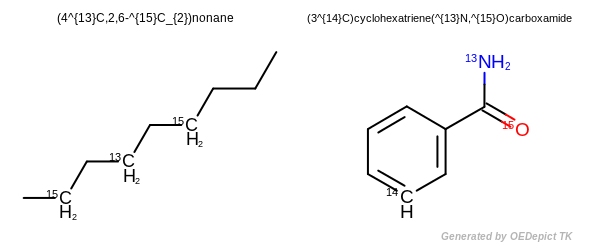
Isotopes
An isotopically substituted compound has a composition such that essentially all the molecules of the compound have only the indicated nuclide at each designated position. For all other positions, the absence of nuclide indication means that the nuclide composition is the natural one [IUPAC-2014].
To name isotopically substituted compounds:
The name of an isotopically substituted compound is formed by inserting in parentheses the nuclide symbol(s), preceded by any necessary locant(s), letters and/or numerals, before the name or preferably before the denomination of that part of the compound that is isotopically substituted. Immediately after the parentheses there is neither space nor hyphen, except that when the name, or a part of a name, includes a preceding locant, a hyphen is inserted. When polysubstitution is possible, the number of atoms substituted is always specified as a right subscript to the atomic symbol(s), even in case of monosubstitution [IUPAC-2014].
For names composed of two or more words:
the isotopic descriptor is placed before the appropriate word or part of the word that includes the nuclide(s), unless unambiguous locants are available or are unnecessary [IUPAC-2014].
For more details, please refer to chapter 8 of the IUPAC Nomenclature of Organic Compounds Draft 2004 [IUPAC-2014].
Output Name Styles
Naming functionality supports the generation of several styles of compound names. The currently predefined name styles are OpenEye (the default), IUPAC, CAS, Traditional and Systematic. OpenEye names loosely correspond to the kinds of names familiar to a medicinal chemist. These names are intended to be a subset of the IUPAC 2005 standard’s acceptable names, but not necessarily the PIN (Preferred IUPAC Name). These correspond to the types of names found in a Sigma-Aldrich catalog or a Journal of Medicinal Chemistry article, for example.
IUPAC names are intended to follow the IUPAC 2005 recommendations for the Preferred IUPAC Name (PIN). Future releases may further refine this definition to provide IUPAC2005, IUPAC93 and IUPAC79 name styles that reflect the corresponding standard’s preferred name.
The CAS name style is intended to follow the Chemical Abstracts Service’s naming conventions, where they differ from IUPAC’s.
The Traditional name style corresponds to forms of compound naming that are now no longer acceptable to the IUPAC rules. The boundary between whether a trivial/common name is considered OpenEye or Traditional when it is acceptable to IUPAC but not preferred is blurred, with OpenEye attempting to follow the more prevalent usage.
Finally, Systematic names correspond to the fully systematic IUPAC names that the IUPAC preferred names are slowly converging towards.
Examples of Name Style Differences
Some of the concepts explained in the previous section are probably best clarified through some real examples.
Example OpenEye vs. IUPAC vs. Systematic Differences
The SMILES string
Ois called ‘water’ by the OpenEye name style, but ‘oxidane’ by the IUPAC and Systematic name styles.The SMILES
C#Cis called ‘acetylene’ by the OpenEye and IUPAC name styles, but ‘ethyne’ by the Systematic name style.The SMILES prefix
*Nc1ccccc1is called ‘anilino’ by the OpenEye and IUPAC name styles, but ‘phenylamino’ by the Systematic name style.The SMILES prefix
*O[N+]#[C-]is called ‘fulminato’ by the OpenEye name style, but ‘isocyanooxy’ by the IUPAC and Systematic name styles.The SMILES prefix
*C(=O)Cis called ‘acetyl’ in the OpenEye and IUPAC name styles, but ‘ethanoyl’ in the Systematic name style.The SMILES string
CC(=O)Cis called ‘acetone’’ in the OpenEye name style, but ‘propan-2-one’ in the IUPAC and Systematic name styles.The SMILES string
C(=O)Ois called ‘formic acid’ in the OpenEye and IUPAC name styles, but ‘methanoic acid’ in the Systematic name style.
Example OpenEye/IUPAC vs. CAS Differences
The SMILES string
c1ccccc1CCCCCCCis named as ‘1-phenylheptane’ by the OpenEye and IUPAC name styles, but as ‘heptylbenzene’ by the CAS name style.The SMILES prefix
*[BH2]is called ‘boranyl’ by the OpenEye and IUPAC name styles, but as ‘boryl’ by the CAS name style.
Example OpenEye/IUPAC vs. Traditional Differences
The SMILES prefix
*Sis called ‘sulfanyl’ by the OpenEye and IUPAC name styles, but as ‘mercapto’ by the Traditional name style.The SMILES string
CCCCCCCCC(=O)Ois called ‘nonanoic acid’ by the OpenEye and IUPAC name styles, but as ‘pelargonic acid’ by the Traditional name style.