Deciding on Clustering Method
The clustering floes in the cheminfo-floes package provide many options for clustering molecules based on their similarity score. This section provides basic guidance on which clustering floe to use based on your application and input data. For brief overviews of each clustering method, and links to specific tutorials, see the methods section.
Floes used in this Tutorial
The floes referenced in this tutorial are:
Decision Tree
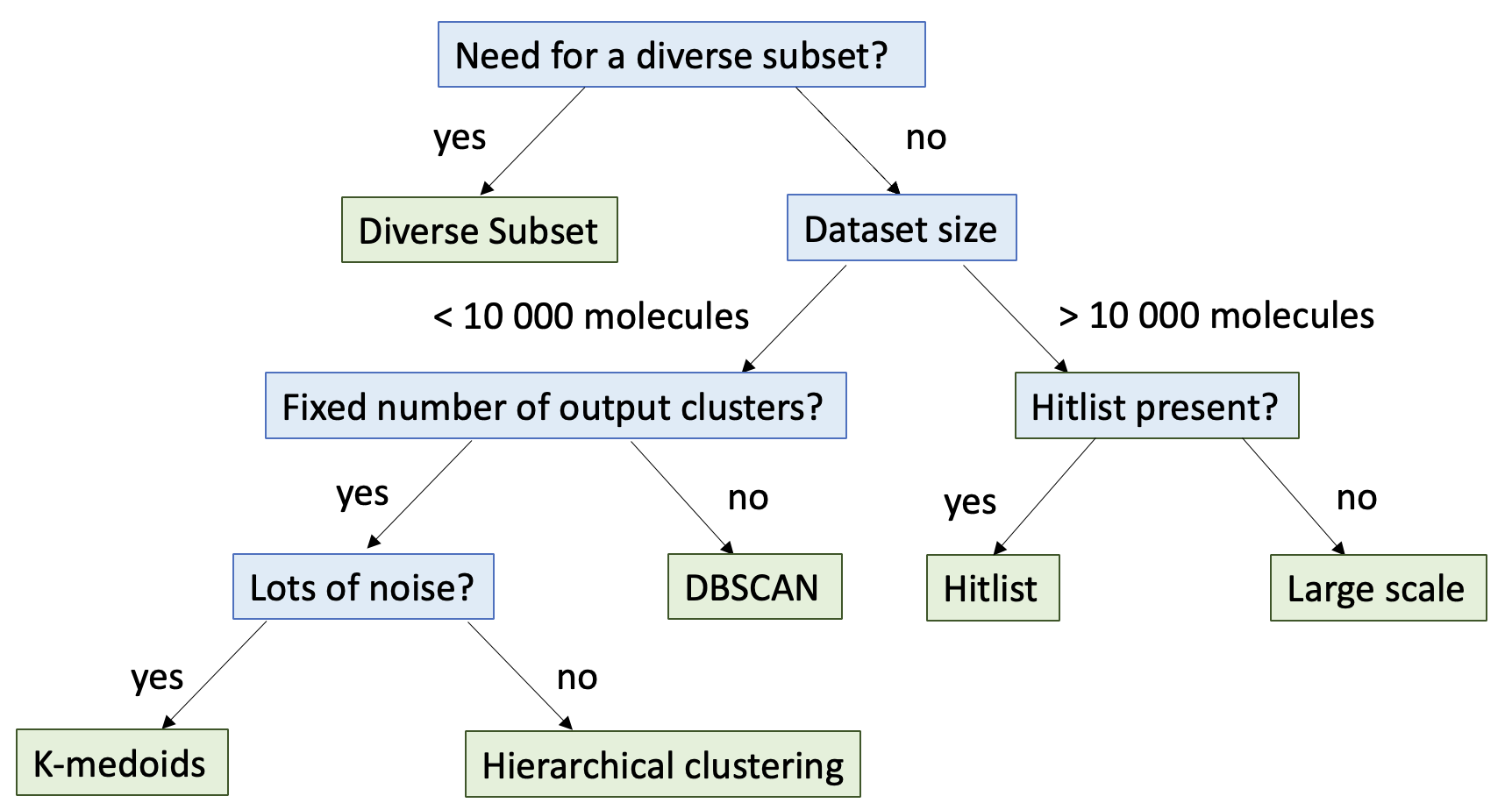
Size Constraints
Is your dataset larger than 10,000 molecules? If so, you are likely to get results much faster using the large scale clustering floes. If the dataset is larger than 30,000 molecules, it will fail the small scale clustering floes.
For datasets smaller than 10,000 molecules, refer to the applications section to decide clustering based on a specific application, or the small scale clustering section for other selection criteria. Please keep in mind that these are only general guidelines for choosing clustering method. It is recommended to consult academic literature to determine the best method for your use case.
Application-Based Clustering
Do you have a specific application in mind for clustering?
Clustering a hitlist: use the Hitlist Clustering floe.
Selecting a specific number of clusters: do you need only the subset?
If yes, use the 2D or 3D Diverse Subset floe.
If no, use the 2D or 3D K-Medoids or 2D or 3D Hierachical Clustering floes.
Small Scale Clustering
Do you want a specific number of clusters?
If yes, you will need to use the hierarchical clustering or k-medoids floes.
If no, and you don’t want to guess the appropriate number of clusters, you will need to use the DBSCAN floe.
Does your dataset have a large number of outliers or lots of noise?
If yes, DBSCAN or k-medoids clustering are less sensitive to outliers. Also, if your dataset has non-globular clusters, or clusters of multiple sizes, DBSCAN is more likely to be effective than k-medoids clustering.
Do you want to have better control over the size of the largest cluster?
If yes, DBSCAN clustering allows you to choose a minimum or maximum size of the largest cluster.
Clustering Methods Overview
DBSCAN Clustering
The 2D and 3D DBSCAN clustering floes use scikit learn’s DBSCAN method to do clustering. DBSCAN stands for Density-Based Spatial Clustering of Applications with Noise. Unlike K-Medoids or hierarchical clustering, DBSCAN views clusters as areas of high density separated by areas of low density. For more details, refer to the sklearn documentation.
K-Medoids Clustering
The 2D and 3D K-Medoids clustering floes use scikit learn extra’s K-Medoids method. K-Medoids tries to minimize the sum of distances between each point and the medoid of its cluster. Its principal advantages are that it can produce the exact number of requested clusters, and that it is less sensitive to outliers than other methods of clustering including k-means and hierarchical clustering. For more details refer to the sklearn documentation on k-medoids.
Hierarchical Clustering
The 2D and 3D hierarchical clustering floes use scikit learn’s AgglomerativeClustering method to do clustering using a bottom up approach. Each member starts in its own cluster, and clusters are merged together in a series of merge steps that occur according to the linkage criteria that is selected. More details can be found in the scikit learn documentation .
Large Scale Clustering
With a large dataset, you have effectively three options for 2D or 3D clustering:
Do you only need a diverse subset? Use the 2D or 3D Diverse Subset floe.
Do you have a hitlist, or another type of dataset that has a score for each molecule? Use the 2D or 3D Hitlist Clustering floe.
If the answer to 1 and 2 is no, use the 2D or 3D Large Scale Clustering floe.
Hitlist Clustering
The 2D or 3D hitlist clustering floes take a large scale input dataset and require a float score field on each record. That score field will be used to direct clustering, and also be used to rank clusters in the clustering report, and provide information about average or best rank in each cluster. For more details, see the hitlist clustering tutorial.
Diverse Subset Floes
The 2D or 3D diverse subset floes take an input dataset, and select N members from that dataset with clustering, using sphere exclusion for large datasets, and k-medoids for small-scale clustering. For large datasets, large scale diverse subset may be significantly faster than clustering itself. For more details, see the diverse subset tutorial.
Large Scale Clustering
The large scale floes use the same method (directed sphere exclusion) as the diverse subset floe and the hitlist floe. Unlike the diverse subset floe, they also output cluster members. Unlike the hitlist clustering floe, they don’t require a score field to be used in clustering, or sorting output clusters. For more details, see the large scale clustering tutorial.