Tutorial: Use Transfer Learning to Rebuild Previous Machine Learning Model Builds Using New Data¶
In machine learning, transfer learning is the process of retraining or repurposing a previously built ML model for a new problem or domain. Imagine having built a QSAR model on solubility on a dataset with molecules of size X. Now, a new set of data whose solubility has been measured comes in; with its size being a fraction of X. These molecules are different from the initial training set, either based on moiety or pharmacophore. We would like to update our previous model to include knowledge of this new data. Consider yet another similar but different problem of built a QSAR model on thermodynamic solubility. We would like to repurpose this model to predict kinetic solubility, as the size of the training data for kinetic solubility is not enough to build a robust model. In both these examples, we wish to reuse previously built robust ML models to extend to a new domain or a new but similar problem.
In this tutorial, we will see how to use the ML ReBuild: Transfer Learn ML Regression Model Using Fingerprints for Small Molecules Floe to train a previously build ML model using transfer learning. Note: we will provide you with a built ML model, but if you want to build one from scratch, refer to the tutorial Building Machine Learning Regression Models for Property Prediction of Small Molecules.
Create a Tutorial Project¶
Note
If you have already created a tutorial project, you can reuse the existing one.
- Log into Orion and click the “Home” button on the navigation bar on the
the Orion Interface. Then click on “Create New Project,”
and in the pop-up window enter Tutorial for the name of the project and click the “Save” button.
Orion home page¶
Floe Inputs¶
The inputs required for the floe are:
Molecule Dataset (P_1) with float response value.
TensorFlow Machine Learning Model Dataset (M_1) to transfer learn on.
For P_1, uploading .csv, .sdf, or similar formats in Orion automatically converts it to a dataset. The solubility dataset contains several *OERecord*(s). The floe expects two things from each record:
An OEMol which is the molecule to train the models on.
A Float value which contains the regression property to be learned. For this example, it is the solubility (log µM) value.
Here is a sample record from the dataset:
OERecord (
*Molecule(Chem.Mol)* : c1ccc(c(c1)NC(=O)N)OC[C@H](CN2CCC3(CC2)Cc4cc(ccc4O3)Cl)O
*Solubility loguM(Float)* : 3.04
)
The M_1 dataset contains one or more machine learning models. To learn how to generate these models, read previous tutorials on building models in Orion.
Input Machine Learning Models
Input Training Dataset
The model has been trained on log µM solubility values from AZ ChEMBL data. The retraining dataset uses a different version of ChEMBL with no common match.
First, the input needs to be selected in the parameter Input Small Molecules to Train Machine Learning Models On.
We can change the default names of the Outputs or leave them as is.
The property to be trained on goes in the Response Value Field under the Options tab. Note that this response value needs to exactly match the response value on which the models in M_1 were trained.
Run OEModel Building Floe¶
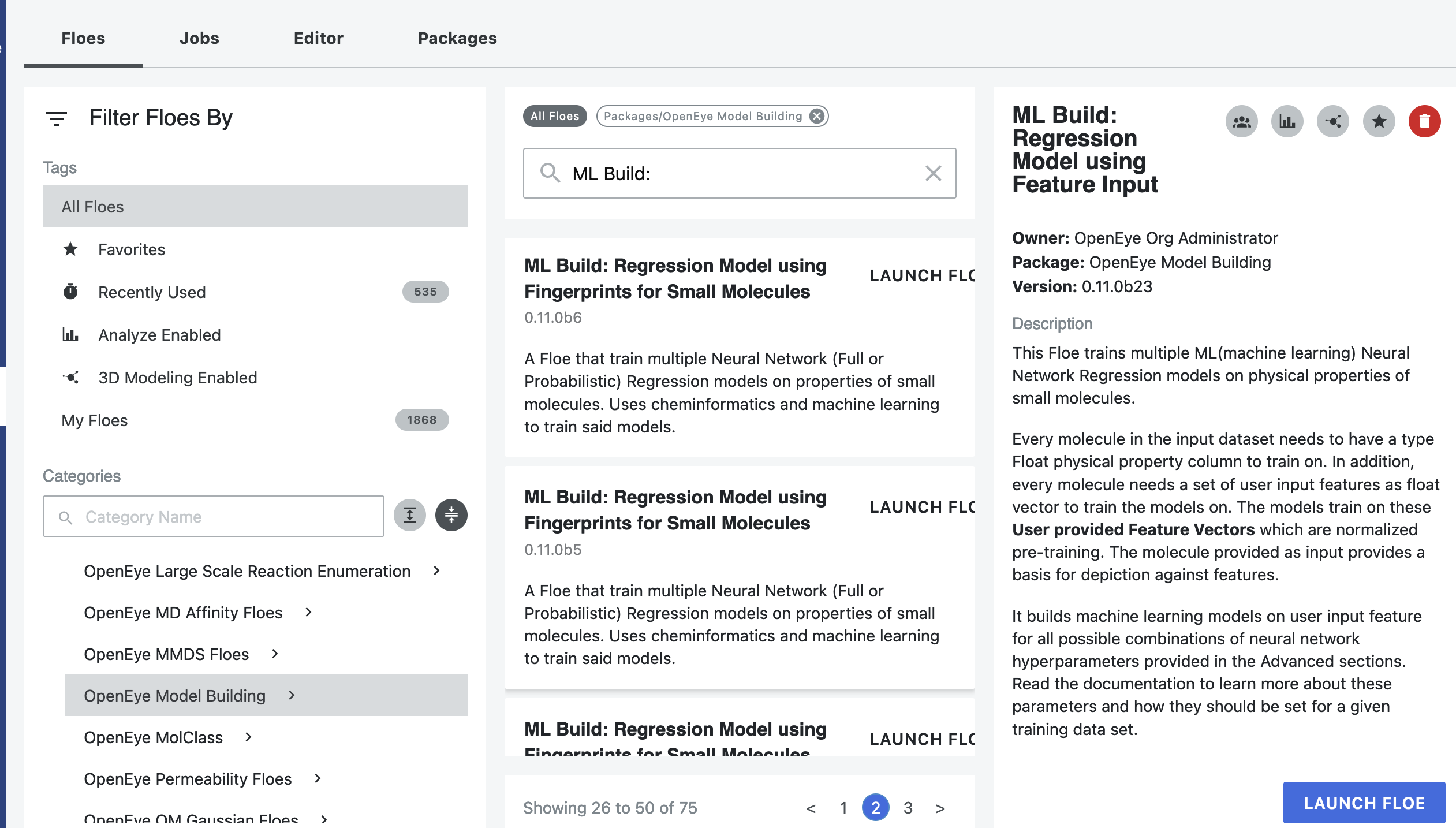
Click on the “Floe” button in the navigation bar.
Click on the Floes Tab.
Under Categories, select the OpenEye Model Building package.
A list of floes will now be visible.
Launch the ML ReBuild: Transfer Learn ML Regression Model Using Fingerprints for Small Molecules Floe, and a Job Form will pop up. Specify the following parameter settings in the Job Form.

Click on the “Choose Input…” button under Input Small Molecules to Train Machine Learning Models.
Select the given dataset P_1 or your own dataset.
Click on the “Choose Input…” button under Input TensorFlow Model.
Select the pretrained solubility model M_1 or your own trained model.
Under Outputs, change the name of the ML models built to be saved in Orion. We will keep it to defaults for this tutorial.
Under the Options tab, do the following:
For the Select models for transfer learning training parameter: if your input ML model dataset has more than one model, you need to pick which model you want to transfer learn on. If the default -1 is retained, it will train all the available models in parallel. This can be expensive if the M_1 you choose has many models.
For our example, M_1 has only one model with model ID 2040. So keeping this parameter to -1 or setting it to 2040 will have the same result.
Select a Response Value Field. This field dynamically generates a list of options to choose based on the input dataset P_1. For our data, it is solubility (log µM). Again, this response value needs to exactly match the response value on which the models in M_1 were trained.
Select how many model reports you want to see in the final Floe Report. This field prevents memory blowup if you generate >1K models. In such cases, viewing the top 20 to 50 models should suffice.
Promoted parameter Preprocess Molecule:
Keeps the largest molecule if more than one is present in a record.
Sets pH value to neutral.
Turn this parameter On.
You can apply the Blockbuster Filter if desired.
If it is necessary to transform the training values (solubility, in this case) to negative log, turn the Negative Log parameter On as well. Keep it off for this example.
As a general rule, you should select the last three options based on what you chose when building the original model.
Finally, select how you want to view the molecule explainer for machine learning results.
Atom annotates every atom by its degree of contribution towards final result.
Fragment annotates every molecule fragment (generated by OEMedChem TK) and is the preferred method of medicinal chemists.
‘Combined’ produces visualisations of both these techniques combined.
Changing layers to train on transfer learn
At the bottom of the Job Form, toggle “Show Cube Parameters” to Yes. Select the Parallel Transfer Learning Neural Network Regression Training Cube. The Layers to Freeze parameter fixes the number of layers in front of the model to NOT train on. Increase this if the retrain data size is smaller than the initial training data.
Click on the green “Launch Floe” button.
That’s it! The floe will run, generate an output, and produce a Floe Report*.
Analysis of Output and Floe Report¶
After the floe has finished running, click the Jobs tab and then the name of the file to reach the Floe Report panel to preview the report. Since the report is large, it may take a few moments to load. Refresh or pop the report into a new window (located in the purple circle in the image below) if this is the case. All results reported in the Floe Report are on the validation data. Note that the Floe Report is designed to give a comparative study of the different models built. In this run, since we have only one model, the graphs may be less insightful.
The Analyze page looks similar to a standard built model, except that there is no hyperparameter tuning. Please refer to the Analysis of Output and Floe Report section of the first tutorial for this information.