Tutorial: Use Small Molecule Data Processing Floe to Preprocess ML Data¶
OpenEye Model Building is a tool to build machine learning models that predicts molecular properties.
Often time, specially when working with open source data, we come across noisy samples with multiple values. This floe attempts to clean such noisy data before they can be fed in an ML framework for training properties. The data processing Floe analyzes and preprocesses data for training ML(machine learning) models. The floe cleans the molecule by retaining the largest molecule (if multiple present in a single record), sets neutral Ph. The floe looks into molecule properties including Mol Wt, Atom Count, XLogP, Rotatable Bonds, and PSA. It cleans outlier molecules sending them to the Failure Port. The floe report gives detailed report on this.
For duplicate molecules, we add a Duplicate warning in the output and include a Box Plot in the floe report indicating the count. For float(regression) response value, the duplicates are set to an average. If the variance of the float value is too high, we reject all the duplicate molecules. For an input string or int response for classification purposes, we set to the highest count of response.
The floe report provides additional details as correlation of response with physical properties, and count of outliers. In this tutorial, we will use the usage of this floe to clean a custom made noisy data.
This tutorial uses the following Floe:
Data Processing of Small Molecules for ML Model Building
Create a Tutorial Project¶
Note
If you have already created a Tutorial project you can re-use the existing one.
Log into Orion and click the home button at the top of the blue ribbon on the left of the Orion Interface. Then click on the ‘Create New Project’ button and in the pop up window enter Tutorial for the name of the project and click ‘Save’.
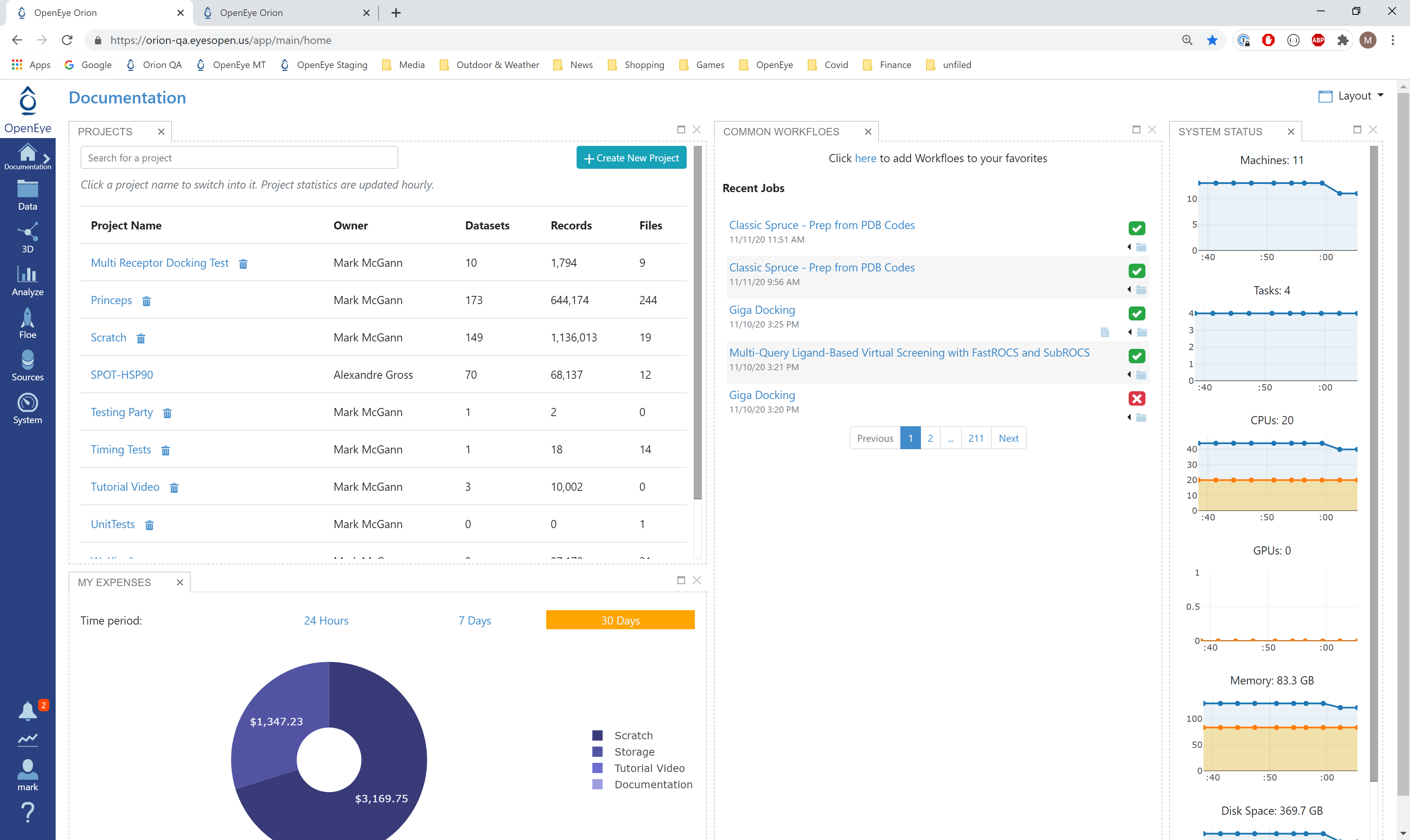
Orion home page¶
Floe Input¶
The inputs required are:
Molecule Dataset (P_1)
- Response Value Field
A Float value for the regression property to be learnt, or
A String/Int value for the classification property. For this example, it is the hERG Class
The P_1 dataset contains several OERecord (s). The Floe expects an OEMol from each record. This is the molecules the model will predict physical property of. Let this dataset be P_1.
Here is a sample record from the dataset:
OERecord (
*Molecule(Chem.Mol)* : Cc1c(c(c(cn1)COP(=O)(O)O)C=O)O
*Herg Class(String)* : Active
)
Input Data
Run Generic Property Prediction Floe¶
Click on the ‘Floe’ button in the left menu bar
Click on the ‘Floes’ tab
Under Categories select Packages
Select OpenEye Model Building
A list of Floes will now be visible.
Click on the Small Molecule Data Processing for ML Model Building and a Job Form will pop up. Specify the following parameter settings in the Job Form.
For the Input Small Molecule Dataset, choose P_1 from above
All the molecules cleaned will be saved to name in the field Output Property. Change it to something recognizable.

Under “Options”, select the “Response Value Field” and set it to the property that will be used to train ML models on. For our example it is the ‘Herg Class’
Keeping ‘Response Analysis’ to ‘Auto’ means the floe will default to classification as the input ‘Herg Class’ is a String (same for Int). Had the response been ‘Float’, it would default to regression. However, there are borderline cases where either the String/Int classes have too many values. The floe suggests using the data to train a regression model instead. On the flip side, if a regression float field has less response values, the floe suggests training a classificaition model.
For our case, we can keep the Response Analysis to Auto or change to Classification
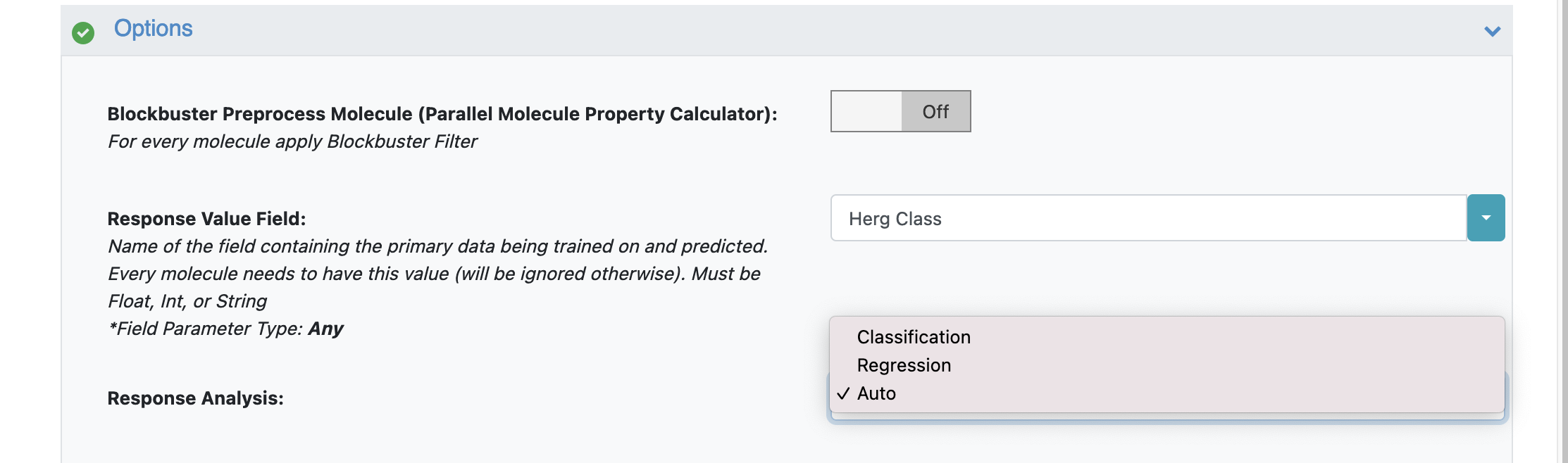
That’s it ! Things should run, generate an output and a Floe report
Analyze Output¶
There are two output ports: Success, Failure.
Go to the data section of Orion and Activate the Output Failure data the Floe produced. This should have the same name you chose for the Output Prediction failure field of your Floe. The data can be activated by clicking on the small plus sign in a circle right next to it.
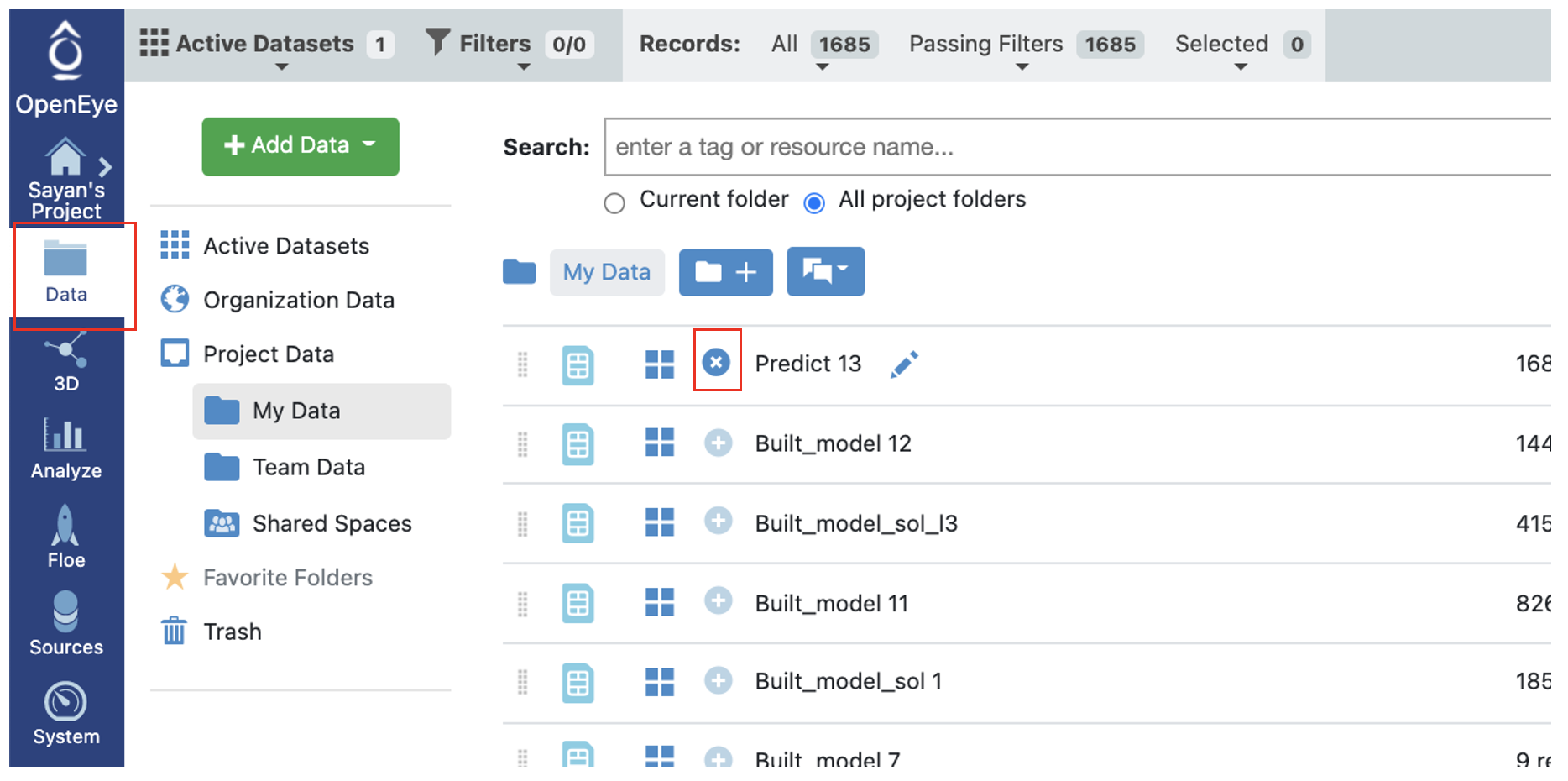
Outputs Meaning
Failure Data: (a) Molecule falls out of scope for physical properties like XlgP, MW. or, (b) It is a duplicate
In the Orion analyze page, you should be able to see the molecules, and the reason they are sent to the failure port. There is another field which states if said molecule was a duplicate and if so, what is the response of the single copy that was sent to success. For classification, if there are n-duplicate molecules, n-1 will be sent to failure, the sole molecule sent to Success will have the median of reponse values. For regression, this will be the average value, unless the spread of response value is too high. Note that this cutoff can be changed under the cube parameter of “Data Process Statistics Calculator” cube.
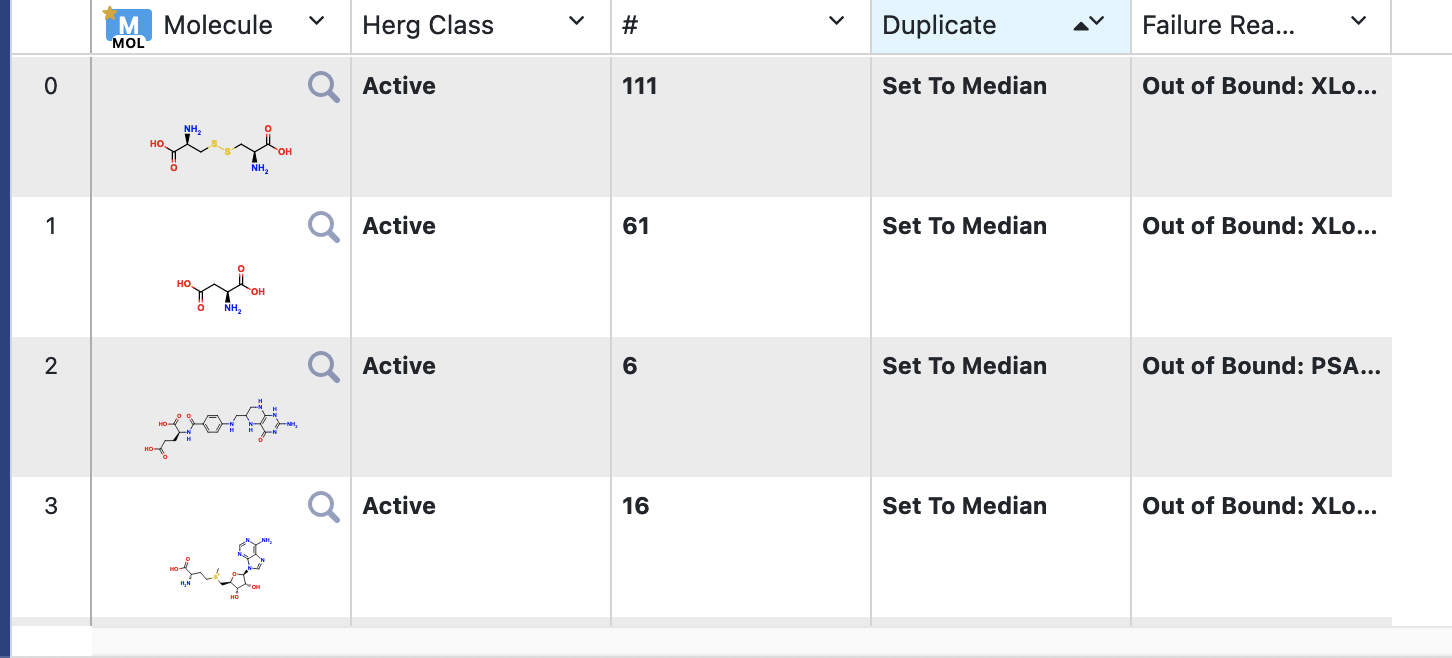
All data not deemed failure will be sent to the Success port
Success Data: (a) Falls within scope; (b) If there were multiple copies of a molecule, this is the first instance and its response is set to Median(for classification example as this), or Average (regression)
Analyze OEModel Floe Report¶
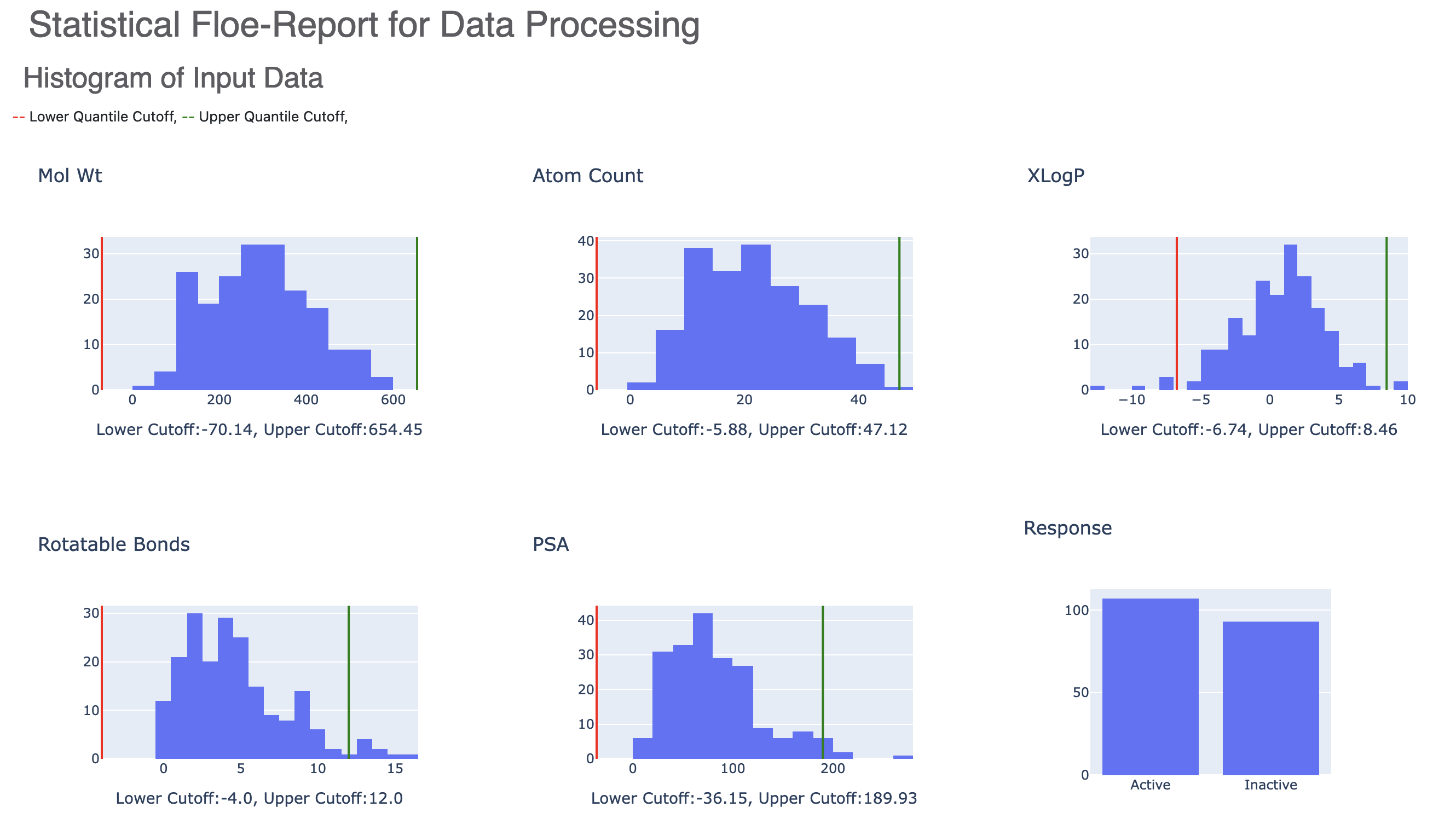
The floe report contains histogram of the input data with the lower and upper quartile in green and red. Any molecule out of these bounds are sent to the failure port. The resulting histogram is also shown in the report.
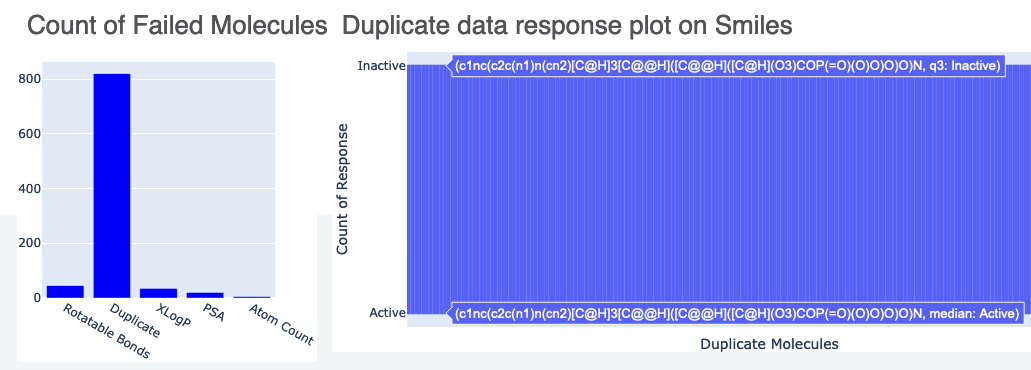
The floe report contains two separate plots. The first bar chats gives count of how many molecules were sent to failure and for what reason. The second plot is a histogram of duplicates. The name and response of these molecules can be seen by hovering over this plot.
The final part of the report contains suggested node size if ML models are to be trained on this data.
